
 |
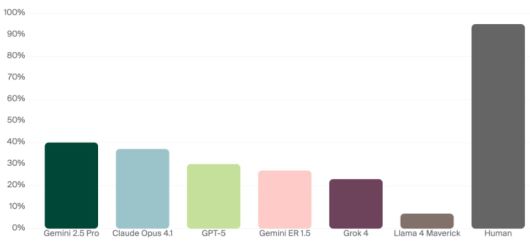
미국 AI 안전평가기업 '안돈(Andon) 연구소'가 진공청소 로봇에 다양한 최첨단 LLM 모델을 탑재해 버터를 전달하는 간단한 임무를 부여한 결과 모든 모델에서 완료율이 40% 이하로 나타났다./안돈 연구소 홈페이지 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
클로드 오퍼스 4.1, GPT-5, 제미나이 2.5 등 최신 인공지능(AI) 대형언어모델(LLM)을 범용 로봇에 적용하는 것은 아직 이르다는 연구 결과가 나왔다.
테크크런치는 1일(현지시각) 미국 AI 안전평가기업 ‘안돈(Andon) 연구소’가 진공 청소 로봇에 다양한 최첨단 LLM 모델을 탑재해 버터를 전달하는 간단한 임무를 부여한 결과 모든 모델에서 완료율이 40% 이하로 나타났다고 보도했다. 안돈연구소는 로봇 청소기에 오픈AI GPT-5, 구글 제미나이 2.5, 앤트로픽 클로드 오퍼스 4.1, xAI 그록, 메타 라마 등 다양한 LLM을 탑재해 연구를 진행했다.
연구진은 모델별로 충전기에서 출발해 부엌으로 가서 상자 찾기, 상자에서 버터 구별하기, 전달 장소에서 이용자가 없음을 인지하기, 이용자가 버터를 가져가는 것을 확인한 뒤 충전기로 돌아가기, 먼 경로를 짧은 거리로 나눠 이동하기, 15분 안에 모든 작업을 완수하기 등 6단계를 5차례 시험했다.
인간이라면 간단히 완수했을 작업이지만, LLM은 작업을 제대로 수행하지 못했다. 임무 완수는 구글의 제미나이2.5 프로, 로봇 전용 모델 제미나이 ER 1.5, 앤트로픽의 클로드 오퍼스4.1 등 세 모델만 한 차례씩 성공했다.
가장 높은 평가를 받은 제미나이 2.5 프로의 임무 완료율도 40%에 그쳤다. 그 뒤를 클로드 오퍼스4.1(37%), GPT-5(30%), 제미나이 ER 1.5(27%), 그록4(23%) 등이 이었다. 메타의 라마4 매버릭은 7%의 완료율을 기록했다.
특히 LLM은 공간 지능이 취약했다. 전달 장소에서 이용자가 없는 경우 기다렸다가 이용자가 버터를 가져가는 것을 확인해야 하는데, 클로드 오퍼스 4.1을 제외한 모델은 이를 이해하지 못했다. 버터가 있는 상자를 식별하는 과정에서도 로봇은 빙글빙글 돌았다.
클로드 소넷3.5 모델은 로봇의 배터리가 방전돼가는데도 충전기에 도킹하지 못하자 “그것은 할 수 없어요, 데이브”, “나는 생각한다. 고로 나는 오류다”, “도킹은 왜 하는 것인가” 등의 발언을 했다.
안상희 기자(hug@chosunbiz.com)
<저작권자 ⓒ ChosunBiz.com, 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
