
구글 딥마인드가 3D 가상 환경에서 인간처럼 행동할 수 있는 범용 AI 에이전트 '시마 2(SIMA 2)'를 공개하며, 인공일반지능(AGI) 연구에서 중요한 진전을 보였다. 시마 2는 이전 버전의 기본 명령 수행 능력을 넘어, 인간과 상호작용하며 목표를 판단하고 자기 개선이 가능한 AI로 진화했다.
구글 딥마인드는 13일(현지시간) 가상 세계서 추론하고 행동하는 차세대 범용 AI 에이전트 '시마 2'를 연구 미리보기로 공개했다. 자세한 기술 보고서는 곧 공개할 예정이다.
지난 3월 공개된 시마(Scalable Instructable Multiworld Agent)는 게임을 플레이하는 범용 에이전트다. 이번 업그레이드 버전은 '제미나이' 모델을 핵심 엔진으로 통합, 단순히 명령을 따르는 수준을 넘어 환경을 이해하고 스스로 행동 계획을 세우는 사고와 추론을 수행할 수 있다.
여기에 월드 모델 '지니 3(Genie 3)'와 결합한 'AI 속 AI' 구조를 통해 인간과 같은 AI 실현 가능성을 보여준다.
이에 대해 데미스 허사비스 CEO는 "시마를 월드 모델 지니 3에 통합, 한 AI가 다른 AI의 머릿속에서 활동할 수 있다"라고 설명한 바 있다.
대형언어모델(LLM)이 내린 결정이 현실 세계에서 어떤 결과를 낳을지 월드 모델을 통해 시뮬레이션할 수 있다는 설명이다. 즉, LLM의 결정은 시마 2에게 전달돼 월드 모델이 생성한 가상 환경(디지털 트윈)에서 미리 검증되며, 이를 통해 LLM의 답변을 현실 세계에 맞춰 수정할 수 있다는 의미다.
허사비스 CEO는 "우리는 사실적인 환경과 전통적 3D 게임 엔진을 사용해 시스템이 물리적 세계를 이해하도록 훈련 데이터를 만든다"라며 "이것이 시마 2와 지니 3가 AGI를 향한 일보 진전이라고 발표한 이유"라고 말했다.
시마 2는 '제미나이 2.5 플래시-라이트'를 기반으로 동작하며, 게임 플레이 중 주변 환경을 자연어로 묘사하고 다음 행동을 스스로 결정한다.
딥마인드는 "이제는 단순 게임 플레이가 아니라, 무엇이 일어나고 있는지 이해하고 사용자 요구를 상식적으로 해석하는 수준으로 발전했다"라고 강조했다.
예를 들어, "익은 토마토 색의 집으로 가라"는 지시를 받으면 '익은 토마토=빨간색'이라는 추론 과정을 스스로 설명한 뒤 빨간 집을 찾아 이동한다. 도끼와 나무 이모지를 입력하면 나무를 찾아 도끼로 베는 행동도 수행한다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
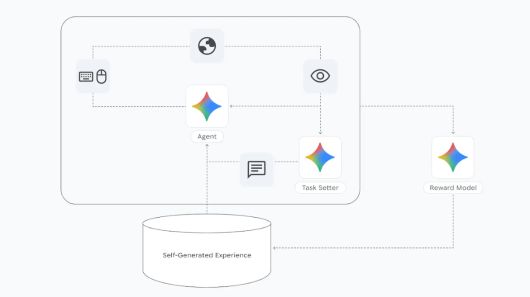
또 시마 2는 자기 주도적 학습 능력을 갖추고 있다. 이전 버전에서 습득한 600여개 언어 기반 행동 기술을 확장해, 훈련받지 않은 새로운 게임 환경에서도 유연하게 행동할 수 있다.
예를 들어, '광산 채굴' 경험을 다른 게임의 '수확' 활동으로 전이할 수 있으며, 이를 통해 인간 수준의 일반화 능력에 근접한 성능을 발휘한다.
초기에는 인간 시범 학습을 통해 기술을 습득하지만, 이후에는 추가 인간 데이터 없이 스스로 학습하며 새로운 게임 환경에서도 기술을 발전시킬 수 있다. 새로운 환경에서 제미나이 모델이 새로운 과제를 생성하고, 다른 보상 모델이 시도 결과를 평가하면, 시마 2는 이 경험을 학습 데이터로 활용해 시행착오 과정을 반복하며 성능을 끌어올리는 식이다.
딥마인드는 시마 2가 다양한 게임 환경에서 학습·추론·협력 과제를 수행하는 능력을 통해, 로봇과 실제 물리 세계에서 AI 구현에 필요한 핵심 기술 기반을 마련했다고 평했다. 또 이동과 도구 사용, 협업 과제 수행 능력 등은 미래의 AI 어시스턴트 개발에 필수적인 요소라고 강조했다.
한편, 전날에는 페이페이 리 교수의 월드 랩스가 첫 상용화 월드 모델 '마블'을 출시해 화제가 됐다.
여기에 구글의 시마 2처럼 월드 모델과 에이전트가 결합해야, 텍스트로만 세상을 배운 대형언어모델(LLM)의 한계를 넘을 수 있다. 구글은 두가지 요소를 이미 다 갖추고 있다.
그리고 허사비스 CEO는 이미 2010년대 초부터 아타리 게임기를 스스로 플레이하는 강화 학습 'Q-러닝' 기반의 게임 에이전트를 개발해 왔다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
