
[뉴스쉽] '혹한기' 예고됐던 반도체 시장 전망 바뀌다
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
'반도체 혹한기' 전망, 한 달 만에 바뀌다
지난 1월 반도체 업종의 재고율은 265%에 달했는데, IMF 직전인 1997년 3월 이후 최고치입니다. 재고율만 보면, 반도체 10개를 시장에 파는 동안 재고는 16개가 쌓이고 있는 것입니다. 당연히 반도체가 남아도니까 가격은 더 떨어질 수밖에 없습니다.
반도체 시장의 혹한기는 이미 지난해부터 예고됐습니다. 급격한 미국의 금리인상과 우크라이나 전쟁 장기화, 중국의 성장 둔화 등으로 반도체가 들어가는 노트북이나 휴대전화 등 상품 수요가 급감할 것이라고 시장은 직감했기 때문입니다. 실제로, 지난 1월 대만의 시장조사업체 트렌드포스는 D램 가격이 올해 1분기에만 20% 하락하고, 2분기에는 11% 추가 하락할 걸로 전망했습니다. 무엇보다 트렌드포스는 반도체에 대한 수요를 공급이 웃도는 지금과 같은 시장 상황은 올해 내내 지속될 걸로 내다봤습니다.
그런데, 한 달 만에 트렌드포스는 전망을 수정했습니다. 올해 4분기부터는 수요가 공급을 추월할 것이라며 지난달 전망을 바꾼 것입니다. 그 사이에 무슨 일이 있던 걸까요?
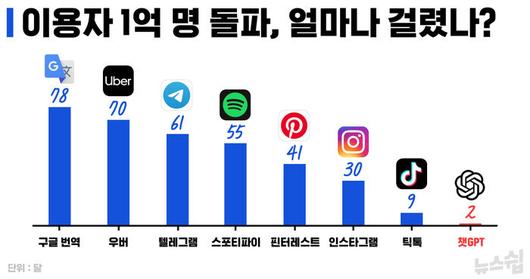
가장 큰 변화는 지난해 11월 말 등장한 '챗GPT'입니다, 챗GPT는 출시 2개월 만에 사용자 1억 명을 넘기며 엄청난, 전례 없는 성공을 거뒀습니다. 빅테크 기업들은 경기 침체 우려에도 불구하고 AI 분야에서만큼은 더 치열하게 경쟁하게 됐고, 이는 곧 반도체 수요 회복으로 이어질 것이라고 전망한 것입니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
그렇다면, 챗GPT는 도대체 무엇일까요? 대규모 언어 모델(Large Language Model)에 기반을 둔 인공지능 기술이라고 하는데......문과생인 저로서는 첫 단어부터 이해하고 넘어가기가 어려웠습니다. 그래서 챗GPT가 '역대급 혹한기'가 예고됐던 반도체 시장의 빅뱅이 될 수 있었는지를 누구나 이해할 수 있게 준비해 봤습니다.
인간을 닮은 기술, AI
챗GPT가 대성공을 거둔 요즘은 챗GPT가 곧 인공지능으로 인식되지만, 알파고가 이세돌과의 바둑 대결에서 승리를 거뒀던 지난 2016년에는 '알파고=인공지능'이라는 등식이 성립됐습니다. 어떤 질문이든 똑 소리 나는 답을 주는 챗GPT와 바둑 천재 이세돌을 이긴 알파고는 별로 비슷한 게 없어 보이는 데 둘 다 인공지능이라니...?!
'복붙' 기능을 만들어 내 우리의 삶을 훨씬 더 편안케 해 준 컴퓨터 과학자 레리 테슬러는 인공지능을 두고 이렇게 설명했습니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
인공지능이 상상도 할 수 없던 방식으로 우리 삶에 스며들면서 그 정의와 쓰임새 모두 무궁무진하게 확장될 수 있다는 의미입니다. 그 끝을 알 수 없다면, 과연 그 시작점은 어디일까?
인공지능이라는 용어를 처음 등장시킨 건 스탠퍼드 대학의 존 매카시 명예 교수입니다. IBM이 1956년 컴퓨터 및 인지과학 분야의 과학자들을 뉴햄프셔 하노버에 초대해 '다트머스 회의'로 알려진 워크숍을 개최했는데, 이 자리에서 존 매카시는 인공지능(AI, Artificial Intelligence)을 인간처럼 지능을 갖고 있는 기계를 만들어내는 과학 및 공학(The science and engineering of making intelligent machines)이라고 정의 내렸습니다.
물론, 인간처럼 생각하고 반응하는 기계에 대한 고민은 그전부터 있었습니다. 영화 '이미테이션'으로 잘 알려진 수학자인 앨런 튜링은 기계가 지능을 갖고 있는지를 판별하기 위한 목적으로 '튜링 테스트'를 조금 앞선 1950년에 만들어내기도 했습니다. 어찌 됐든 AI는 인간처럼 생각하고 반응하며 학습하는 기계에 대한 오랜 염원에서 시작됐습니다. 이를 위해 과학자들은 인간의 두뇌에 주목했습니다. 인간의 사고방식을 파악해 기계에 적용한다면, 기계도 인간처럼 지적인 존재가 될 수 있다고 생각한 것입니다.
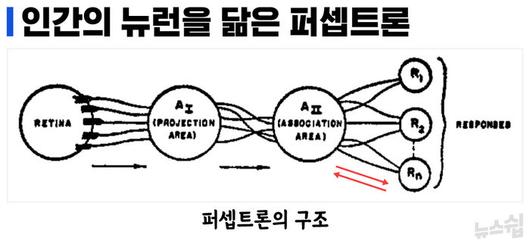
인간을 모방한 최초의 인공지능은 퍼셉트론이라 할 수 있습니다. 퍼셉트론은 프랭크 로젠블라트가 1958년 자신의 연구 보고서 <퍼셉트론 : 두뇌의 정보 저장과 구성에 대한 확률 모델>에서 제시한 수학적 알고리즘입니다. 뇌 속 뉴런의 활동을 수학적으로 풀어내 기계에 적용한 것입니다. 이런 시도는 그전에도 있었지만, 로젠블라트가 특별했던 이유는 '학습'이라는 요소를 추가했기 때문입니다. 알고리즘이 학습을 한다니?... 이게 무슨 말일까. 로젠블라트는 퍼셉트론의 구조를 아래와 같이 표현하고 있습니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
퍼셉트론에서 주목할 점은, 한 방향으로 향하던 신호가 마지막 부분에서는 다시 역방향으로 흐른다는 점입니다. 로젠블라트가 이를 통해 표현하고자 했던 함의는 자기가 만든 퍼셉트론이라는 수학적 알고리즘은 결과 값이 나오고 끝나는 게 아니라는 것입니다. 대신 결과 값의 오차를 반영해 이전 과정에 다시 피드백을 줍니다. 이를 통해 알고리즘은 스스로 가중치를 교정하며 점차 정답에 가까워집니다. 로젠블라트는 이런 과정을 거쳐 퍼셉트론도 학습할 수 있다고 믿었습니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
로젠블라트는 1958년 7월 당시 IBM704 컴퓨터를 통해 퍼셉트론을 시연했습니다. 사람의 개입 없이 IBM704 스스로 왼쪽에 사각형 모양이 표시된 펀치카드와 오른쪽에 사각형 모양이 표시된 펀치카드를 구별하는 실험이었는데, 50번의 시행착오를 거친 끝에 펀치카드를 정확하게 구별해 내기 시작했습니다. 인간처럼 스스로 학습하는 기계가 세상에 등장한 겁니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
세포에서 신경망으로
뉴욕타임스는 퍼셉트론이 혹한기를 맞고 있는 반도체 시장의 구세주가 될 것이라는 점을 반세기도 더 전에 예측을 한 것일까요? 안타깝게도, 퍼셉트론은 오늘날 AI 기술의 기초가 된 것은 맞지만 1950년대의 IBM704로도 충분히 구현할 수 있었습니다. 오늘날 폭발적인 반도체 수요를 초래한 기술은 아닙니다.
퍼셉트론은 놀라운 발견이었지만, 치명적인 한계도 있습니다. 퍼센트론은 학습을 통해 1 또는 0, 참 아니면 거짓이라는 답을 산출해 낼 수 있습니다. 앞서 설명한 시연에서도 퍼셉트론은 '왼쪽이냐? 오른쪽이냐?'처럼 이분법적인 구분을 통해 해결하는 선형적 문제를 해결했습니다. 그런데 1969년의 어느 날, 또 다른 인공지능의 대가 마빈 민스키가 <Perceptrons>라는 책을 펴내 단일 퍼셉트론으로는 배타적 논리합(XOR)과 같은 비선형 문제를 해결할 수 없다는 점을 증명해 냈습니다.
민스키의 증명이 중요한 이유는 바로 '논리 게이트(Logic Gate)'에 있습니다. 스마트폰 등의 전자 회로를 구성하는 기본 단위인 논리 게이트는 논리곱(AND), 논리합(OR), 배타적 논리합(XOR), 논리 부정(NOT), 부정 논리곱(NAND), 부정 논리합(NOR), 부정 배타적 논리합(NXOR) 등 모두 일곱 가지 논리 연산으로 이뤄져 있습니다. 인공지능의 가장 기초 단위인 퍼셉트론이 논리 연산들을 모두 다 해결할 수 있어야 전자 회로 등을 통해 구현될 수 있습니다.
그러나 퍼셉트론이 선형적 논리연산들(AND, OR, NAND, NOR)은 잘 해결하지만 비선형적 논리 연산들(XOR, NXOR)은 해결하지 못한다는 점이 민스키의 증명으로 분명해졌고, 인공지능 기술 발전에는 20년 가까운 암흑기가 찾아옵니다.
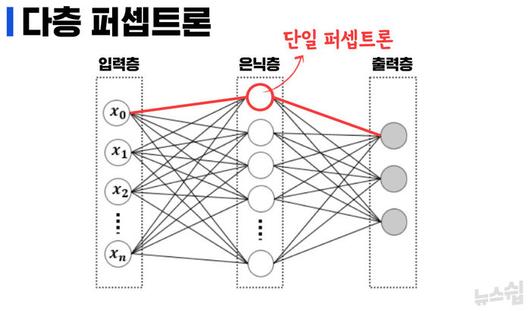
암흑기에 빠져나올 수 있었던 건 퍼셉트론을 여러 겹으로 쌓기 시작하면서입니다. 비유하자면, 곱셈과 나눗셈은 할 줄 모르지만 덧셈과 뺄셈은 할 줄 아는 어린아이에게 더하기와 빼기를 여러 번 해서 같은 결과를 얻을 수 있는 우회적 방법을 알려주는 셈입니다. 대신, 연산을 더 많이 해야 하는 만큼 퍼셉트론도 하나가 아니라 여러 개가 필요하게 됐습니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
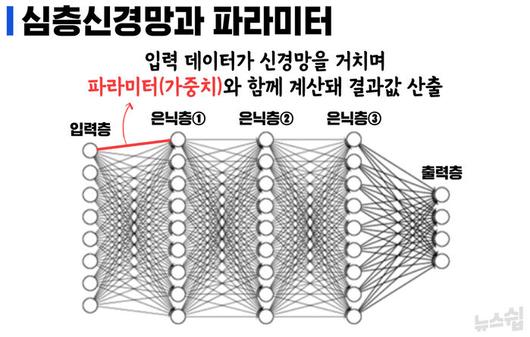
퍼셉트론을 여러 개 쌓으면서 탄생한 다층 퍼셉트론은 세포를 넘어서 인간의 신경망까지 AI 기술이 모방해 낸 결과입니다. 다층 퍼셉트론은 입력층과 출력층이 있고 둘 사이에 숨겨져 있는 은닉층이 있습니다. 통상 다층 퍼셉트론부터 인공신경망(Artificial Neural Network)으로 이해하는데, 은닉층이 많아 신경망의 깊이가 깊고 복잡해 어려운 연산에 활용되는 것을 심층신경망(Deep Neural Network)이라 부릅니다. 바둑 천재 이세돌을 꺾은 알파고도, 똑 소리는 나는 천재 AI 챗GPT도 바로 심층신경망을 통한 학습(딥러닝) 덕분에 가능했습니다.
AI, 반도체 먹는 하마
어떤 정보를 입력받든 1 또는 0으로만 출력해 내는 퍼셉트론이 바둑도 두고 변호사 시험도 통과하는 초거대 AI로 거듭날 수 있던 토대는 앞서 설명한 로젠블라트의 '가중치를 통한 학습'과 민스키의 증명에서 비롯된 '다층 퍼셉트론'이라고 생각합니다.* 덕분에 깊고 복잡한 신경망을 구성할 수 있게 됐고, 신경망을 오가는 과정에서 셀 수 없이 많은 가중치가 부여되면서 인공지능은 더 정확한 판단을 할 수 있게 됐기 때문입니다.
*인공지능 발전 과정을 상당히 축약하다 보니, 제프리 힌튼 교수 등의 '역전파 학습'에 대한 연구 성과, 구글이 2017년 발표한 언어 모델 '트랜스포머' 등에 대한 내용은 부득이 생략했음을 밝힙니다.
가중치는 '파라미터(Parameter, 매개변수로 번역)'로도 이해되는데, 이 파라미터의 규모가 오늘날 인공지능의 성능을 결정짓고 있습니다. 실제로 지난해 11월 말 출시된 챗GPT는 오픈AI에서 개발한 대형 언어 모델 GPT-3의 한 버전(3.5)으로 파라미터 수만 1,750억 개에 달하는 초거대 AI입니다. GPT3 이전 모델인 GPT2는 파라미터가 15억 개였고, 그 이전 모델인 GPT1은 1억 1,700만 개였습니다. 버전을 달리하며 파라미터 수가 기하급수적으로 늘어났고, 성능도 비약적으로 발전한 것입니다. 최근 모습을 드러내자마자 '변곡점'이라 평가받고 있는 GPT4 모델의 파라미터는 인간 뇌의 시냅스와 같은 100조 개에 달할 걸로 추정됩니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
앞으로 우리가 쓰게 될 인공지능의 파라미터가 100조 개에 달한다면, 이용자의 질문을 인식하고 정확한 답변을 제시하는 과정에서 얼마나 많은 연산을 해야 할까요? 더구나, 하루에도 수십, 수백 만 명의 이용자가 온갖 질문을 던집니다. 필요한 연산 규모는 정확히 알 수 없지만, 확실한 것은 사람이 할 수는 없다는 것입니다.
그래서 필요한 것이 반도체입니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
반도체는 인공지능의 대가들이 이룩해 놓은 소프트웨어를 물질세계에서 구현해 내는 하드웨어입니다. 통상 반도체 중에서도 논리 연산을 수행하며 정보 처리 업무를 담당하는 것을 '시스템 반도체'로 분류합니다. 대표적인 것이 CPU(Central Processing Unit, 중앙처리장치)입니다. CPU 안에 있는 산술논리연산장치(Arithmetic and Logical Unit)가 이름에서도 드러나듯 정보 처리 업무를 담당합니다. 이런 CPU가 인공지능을 뒷받침할 때 놀라운 성과를 냈는데요.
미국 스탠퍼드 대학의 교수이자, 중국의 IT 기업인 바이두의 인공지능 연구를 이끌기도 했던 앤드류 응은 지난 2012년에는 구글과 유튜브 동영상을 캡처한 이미지 1,000만 개를 이용해 10억 개의 파라미터를 가진 딥러닝 모델을 학습시키는 프로젝트를 진행했습니다. 1,000만 개의 이미지를 3일 동안 학습했는데, CPU 2,000개가 사용됐기에 가능했습니다.*
*이 프로젝트는 '비지도학습'을 통한 이미지 인식 분야의 성과로 알려져 있지만, 인공지능과 반도체의 관계를 설명하는 과정에서 관련 설명을 부득이 생략했습니다.
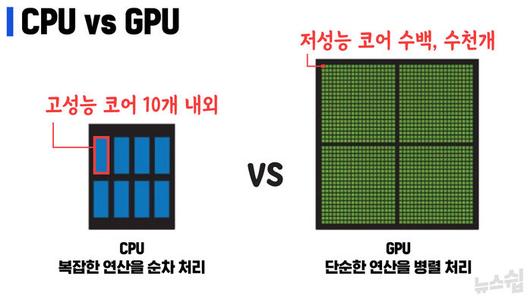
하지만, 한계도 있었습니다. CPU는 아주 복잡한 연산을 잘 처리하기는 하지만 순차적으로 정보를 처리하기 때문에 셀 수 없이 많은 정보를 학습시켜 판단의 정확도를 높이는 딥러닝 모델에는 완전히 딱 맞는 옷은 아니었습니다.
오히려 CPU 보다는 단순한 연산을 처리하지만 순차적인 방식이 아니라 병렬적인 방식으로 정보를 처리하는 GPU(Graphics Processing Unit, 그래픽 처리 장치)가 딥러닝에 비용이나 효율성 측면에서 더 적합했습니다. 실제로, 2012년에 이뤄진 앤드류 응 교수의 프로젝트를 CPU를 대신해서 GPU를 사용해서 진행했더니 고작 12개만 필요했습니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
GPU는 원래 CPU를 보조하는 그래픽 처리용으로 개발됐습니다. CPU로부터 일부 연산 업무를 하청 받아서 처리해 왔던 것인데, 엔비디아라는 미국의 반도체 펩리스 기업이 2006년 'CUDA'를 내놓으면서 판도가 바뀌었습니다. CUDA는 그래픽만 처리하던 GPU를 연산 전용 장치로 탈바꿈시키는 일종의 설계도인데, 이를 통해서 생산된 반도체가 GPGPU(General-Purpose computing on Graphics Processing Units, 범용 그래픽 처리 장치)입니다.
현재는 GPU와 GPGPU를 따로 구분하지 않고 GPU로 통칭해서 부르고 있습니다. 병렬 연산의 장점을 극대화한 GPU는 AI에 적합한 반도체로 스스로를 어필했고, 챗GPT가 최근 대성공을 거둔 지금 그 어느 때보다 크게 주목받고 있습니다. 덕분에 GPU 시장을 꽉 쥐고 있는 엔비디아는 인텔과 TSMC, 삼성전자 등 기라성 같은 반도체 기업들과 경쟁하며 시장의 판도를 흔들고 있습니다.
이쯤에서 이런 지적이 나올 수 있습니다.
"기자 양반, 서두에 언급한 트렌드포스의 전망은 메모리 반도체 D램에 대한 것 아니었나요?"
네, 맞습니다. D램에 대한 이야기로 넘어가 보면, 인간의 연산 과정에는 우리가 의식하지 못하는 사이에 '기억'이 작용합니다. 인간의 이성을 아주 철저히 분석한 철학자 이마누엘 칸트는 자신의 저서 <순수이성비판>에서 이런 내용을 잘 정리했는데요. 1+1+1+1이라는 아주 단순한 연산 과정을 틀리지 않기 위해서 우리는 반드시 직전 연산의 결과를 제대로 기억하고 있어야 합니다.
더하기는 할 줄 알지만 기억은 하지 못한다면 1+1+1+1의 답은 4가 아니라 언제나 2가 나올 것입니다.(직전의 연산 과정은 기억하지 못하기 때문입니다.) 이는 연산뿐만 아니라 생각하고 말하며, 읽고 쓰는 인간의 모든 지적활동에 적용되는데요. 인간의 사고방식을 모방해 놓고는 이젠 인간을 뛰어넘는 퍼포먼스를 보여주고 있는 챗GPT도 마찬가지입니다.
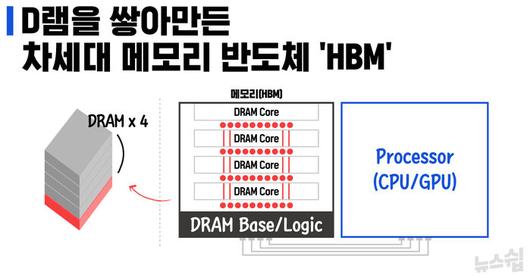
챗GPT가 수면 위에서 고고한 천재처럼 시크하게 답을 내놓을 때, 수면 아래에서는 GPU가 쉴 새 없이 연산을 수행합니다. 제대로 연산 작업을 수행하려면 앞서 살펴본 인간의 의식 작용처럼 매 연산마다 결과를 기억하고 새로운 연산에 적용할 수 있어야 합니다. 이때 필요한 것이 바로 메모리 반도체입니다. 그것도 일반적인 메모리 반도체가 아니라 HBM(High Bandwidth Memory, 고대역폭 메모리)이 필요합니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
HBM은 D램을 수직으로 적층하는 구조입니다. 손톱 크기에 불과한 D램 칩에 5천~8천 개의 미세한 구멍을 뚫어 연결하는 '실리콘 관통 전극(TSV)'이란 기술로 만든 것인데, 최대 12개 층으로 쌓을 수 있습니다. D램이 하나가 들어갈 자리에 여러 개를 쌓아놓고 연결하는 것이기 때문에 당연히 면적 대비 용량이 개선됩니다. 뿐만 아니라 대역폭도 훨씬 나아집니다.
메모리 반도체에 있던 데이터를 프로세서가 끌어올 때, 기존 D램에서는 1차선 도로를 타고 정보가 이동했다면, D램 여러 개를 적층한 HBM에서는 16차선 도로를 따라 정보가 이동할 수 있게 됩니다. 물론 각 차선마다 속도는 많이 떨어지지만, 현재는 세대를 거듭하면서 차선 별 속도까지 6배 이상 나아져 모바일용 D램이나 서버용 D램과는 비교할 수 없이 많은 데이터를 프로세서와 주고받을 수 있습니다. 수많은 데이터를 수시로 저장했다가 끌어오며 연산을 수행해야 하는 GPU에게 HBM은 최고의 파트너일 수밖에 없는 것입니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
최근 젠슨 황 엔비디아 CEO는 챗GPT와 같은 생성형 AI를 위한 새로운 GPU 모델인 H100을 공개했는데, 이 모델에 들어가는 메모리 반도체는 바로 4세대 HBM인 'HBM3'입니다. 여기서 주목할 점은 HBM3은 우리 기업인 SK하이닉스와 삼성전자만이 대량 생산을 통해 시장에 공급할 수 있다는 것입니다. HBM이 전체 D램 시장에서 차지하는 비중이 아직은 큰 편은 아니지만, 챗GPT의 등장과 성공으로 인공지능 시대가 현실로 성큼 다가오면서 가장 주목받는 차세대 메모리 반도체임에는 분명합니다.
그간 메모리 반도체 시장의 대표 상품은 D램과 낸드였습니다. 인텔의 CPU나 엔비디아의 GPU, 퀄컴의 AP처럼 수요에 맞춰 생산하는 맞춤형 제품이 아닙니다. 제조사가 삼성이든 SK하이닉스든, 마이크론이든 간에 시장에 나와 있는 싼 것을 골라 쓸 수 있기 때문에 더 싼 값에 더 많은 양을 공급해야만 했습니다. 그렇다 보니, 나중에 공급량이 수요를 추월하게 되면 개당 가격이 2달러 밑으로 떨어지는 덤핑경쟁까지 벌이며 시장에서 생존해내야 합니다.
그러나 HBM은 다릅니다. 앞서 살펴본 것처럼 챗GPT를 현실적으로 유일하게 가동할 수 있는 엔비디아의 GPU에 함께 패키징되고 높은 진입장벽 덕에 우리 기업들만 생산하고 있습니다. 덤핑경쟁을 벌일 필요가 없이 수요에 맞춰 생산할 수 있는 상황입니다.
무엇보다 HBM은 모바일용 D램보다는 10배 정도 비싼 고부가가치 상품입니다.(정확한 가격은 공개되지 않았습니다.) HBM으로 인해 메모리 반도체의 비즈니스 모델이 송두리째 바뀔 수도 있는 것입니다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
안상우 기자(asw@sbs.co.kr)
▶ 네이버에서 SBS뉴스를 구독해주세요!
▶ 가장 확실한 SBS 제보 [클릭!]
* 제보하기: sbs8news@sbs.co.kr / 02-2113-6000 / 카카오톡 @SBS제보
※ ⓒ SBS & SBS Digital News Lab. : 무단복제 및 재배포 금지
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
