
구글의 새로운 자연어처리(NLP) 모델 ‘T5’는 특정 영역의 학습된 모델을 다른 영역에서도 사용할 수 있는 ‘전이학습’을 이용한 기계 학습 모델이다. 실제로 T5는 많은 자연어처리 벤치마크에서 가장 높은 점수를 주고 있다. 실제로 T5와 퀴즈 대결을 할 수 있는 웹 사이트도 공개됐다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
구글 T5는 지난해 10월 24일(현지시각) 아카이브(arXiv) 학술 플랫폼에 논문 ‘통합 텍스트-텍스트 변환기를 이용한 전이학습의 한계 탐색(Exploring the Limits of Transfer Learning with a Unified Text -to-Text Transformer)’를 발표하며 등장했다.
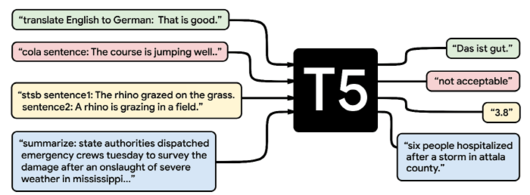
특히 구글이 개발한 자연어처리 모델 BERT는 클래스 레이블이나 입력 범위와 같은 인간이 언어 그대로 이해할 수 없는 데이터만 출력할 수 있는 반면, T5는 입력과 출력이 항상 텍스트 형식이 되도록 자연어처리 작업을 재구성했다. 따라서 기계 번역이나 문서 요약에 유연하게 대응할 수 있다.
T5의 성능을 뒷받침하는 것은 'C4'라는 데이터 세트다. 구글이 개발한 이 데이터 세트는 웹 스크레핑에 의해 준비된 데이터 세트인 ‘CommonCrawl’에서 중복되거나 불완전한 문장, 과격한 내용, 노이즈를 제거해 110억의 파라미터를 가진 커다란 데이터 세트를 확보하고 고품질과 다양성이 담보되어 있다. C4는 기계 학습 플랫폼 ‘텐서플로(TensorFlow)’에서 누구나 사용할 수 있다.
T5 개발을 위해 구글은 지금까지 전이학습을 통한 자연어처리 모델의 구현 방법을 조사한 결과 다음과 같은 통찰을 얻었다.
▲모델 구조: 일반적으로 디코더 모델보다 엔코더 디코더 모델 쪽 성능이 높다. ▲사전 학습 목표: 공백이 있는 불완전한 문장을 이용한 보충 형식의 학습이 계산 비용 측면에서 가장 성능이 높다. ▲미 레이블 데이터 세트: 작은 데이터 세트에 의한 사전 학습은 유해한 과잉 준수로 이어질 수 있다. ▲학습전략: 멀티태스킹 학습은 각각의 작업을 학습시키는 빈도를 신중하게 검토할 필요가 있다. ▲규모: 사전 학습에 사용된 모델의 크기, 학습시간, 앙상블 학습에 사용된 모델 수를 비교하고, 제한된 계산 자원을 가장 효율적으로 사용하는 방법을 결정한다.
위와 같은 통찰과 학습에 사용하는 C4 데이터 세트 크기가 수많은 벤치마크에서 최고 점수를 내는 결과로 이어지고 있다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
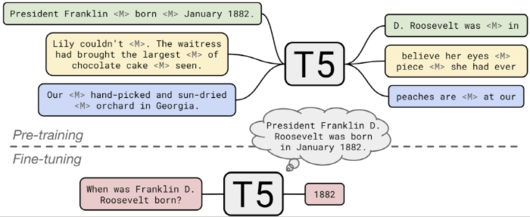
특히 T5는 혁신적인 2가지 능력을 갖추고 있으며, 그중 하나가 ‘알 수 없는 질문에 대한 답변’이다. T5는 사전 학습에서 질문과 질문에 대한 답변의 배경을 부여하고, 그 배경을 고려해 질문에 답변하도록 훈련되어 있다.
예를 들어 “허리케인 코니는 언제 발생했는가”라는 질문과 함께 위키피디아(Wikipedia)의 코니에 관한 기사를 동시에 주면 T5는 기사의 날짜인 1955년 8월 3일을 찾을 수 있도록 훈련되어 있다. 또한 T5는 외부 데이터에 접근하지 않고 사전학습 시에 입력된 데이터만을 바탕으로 질문에 대답하는 자신만의 ‘지식’을 가진 자연어처리 모델이다.
다음 사이트 T5 trivia에 들어가면 실제로 T5와 퀴즈 대결을 할 수 있다. 또한 T5의 소스 코드는 깃허브(GitHub)에 공개되어 있어 누구라도 사용할 수 있다.
김들풀 기자 itnews@
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
