
MLPerf서 NVFP4 기반 훈련 성능 입증
24일 엔비디아에 따르면 글로벌 AI 반도체 벤치마크 대회인 엠엘퍼프(MLPerf) 훈련·추론 비공개 부문에서 NVFP4 기반 성능을 제출했다. 모든 거대언어모델(LLM) 테스트 항목에서 정확도 기준을 충족했다는 설명이다.
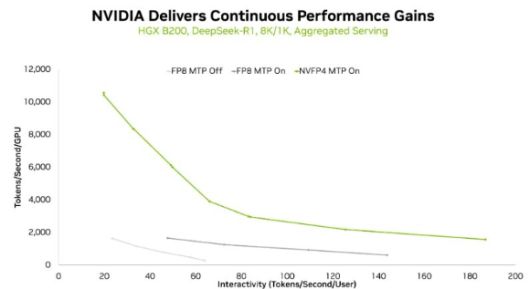 |
NVFP4를 적용했을 때가 FP8 대비 GPU당 토큰 처리량이 가장 높게 나타난 모습. [자료=엔비디아] |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
블랙웰 울트라 GPU는 NVFP4 기준 최대 15페타플롭스(PF·1PF는 1초에 1000조 번 연산)의 처리량을 제공한다. 이는 기존 8비트 부동소수점(FP8) 방식 대비 최대 3배 높은 수준이다.
테스트에서도 속도 차이가 나타났다. 블랙웰 울트라 GPU 512개를 묶은 'GB300 NVL72' 시스템은 초대형 AI 모델 '라마 3.1 405B'(4050억 개 매개변수)를 64.6분 만에 사전 훈련했다.
이는 이전 세대인 GB200 NVL72 시스템(FP8 적용) 대비 1.9배 빠른 기록이다.
추론 성능도 개선됐다. 6710억 개 매개변수를 가진 대형 모델 '딥시크-R1'에 NVFP4를 적용한 결과, 동일한 조건에서 토큰 처리량이 늘고 응답 지연이 줄었다.
딥시크-R1과 라마 3.1 8B·405B, 라마 2 70B 등에서도 기준선 수준의 성능을 유지했다는 설명이다.
엔비디아는 차세대 GPU '루빈'도 예고했다. 루빈은 NVFP4 기준 훈련 성능을 현재 블랙웰 대비 3.5배, 추론 성능은 5배 높이는 것을 목표로 한다.
/권서아 기자(seoahkwon@inews24.com)
[ⓒ 아이뉴스24 무단전재 및 재배포 금지]
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
