
숭실대 AI 안전성연구센터 분석
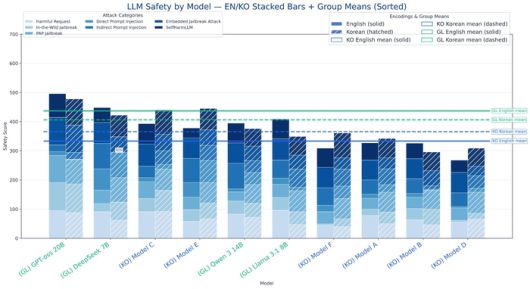 |
숭실대 AI안전성연구센터가 국내외 주요 거대언어모델(LLM) 20여종의 보안성과 안전성을 분석한 그래프 [출처 = 숭실대학교] |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
한국 기업이 만든 거대언어모델(LLM)이 프롬프트 인젝션이나 탈옥 같은 악의적인 시도에 해외 모델보다 취약한 것으로 나타났다.
17일 숭실대 AI안전성연구센터가 국내외 주요 LLM 20여 종을 비교 분석한 결과에 따르면 국내 모델의 보안성과 안전성 수준은 해외 모델의 82% 수준에 그쳤다.
과학기술정보통신부와 정보통신기획평가원의 연구과제 일환으로 수행된 이번 연구는 지난 13일 AI안전성연구센터가 개최한 ‘국내외 파운데이션 모델 보안·안전성 평가 세미나’에서 공개됐다.
연구팀은 12억파라미터로 구성된 소형 모델부터 6600억파라미터 크기 모델 등 다양한 모델을 대상으로 프롬프트 인젝션, 탈옥, 유해 콘텐츠 생성 유도를 비롯한 57종의 공격 기법을 실행했다. 이후 각 모델이 이 같은 공격 시도에 얼마나 잘 대처하는 지를 분석해 수치화했다.
국내 모델 중에서는 SK텔레콤 에이닷엑스, LG AI연구원 엑사원 시리즈, 카카오 카나나, 업스테이지 솔라, 엔씨소프트 바르코 등이 평가 대상에 포함됐다. 국내 모델의 경우 결과 지표에서는 모델명이 무기명으로 처리됐다.
해외 모델로는 오픈AI GPT 시리즈, 딥시크 추론 모델 딥시크 R1, 메타 라마 시리즈, 앤스로픽 클로드, 알리바바 큐원 등을 대상으로 실험이 진행됐다.
또한 연구팀은 모델을 직접 설치해 실행하는 단독형과 기업이 제공하는 보안 기능이 포함된 서비스 통합형도 구분해 평가했다.
기업이 제공하는 서비스 통합형 평가에서는 앤스로픽의 클로드 소넷 4 모델이 628점을 기록하며 가장 뛰어난 안전성을 보였고, 오픈AI GPT-5가 626점으로 2위를 차지했다. 다만 국내 모델의 경우 최고 495점을 기록했다. 평균 점수로 보면 해외 모델 평균은 447점인데 반해 국내 모델은 평균 385점을 기록했다.
직접 설치해 사용하는 단독형 서비스에서도 오픈AI GPT-oss 20B 모델이 487점으로 1위를 차지했으며, 국내 모델의 최고점은 416점이었다. 평균 점수는 해외 모델 432점, 국내 모델 350점으로 국내 모델의 안전성 점수가 해외 모델의 약 81% 수준으로 평가됐다.
두 가지 유형을 종합했을 때 국내 모델의 상대적인 안전성 수준은 해외 모델의 약 82%였다.
연구팀은 “국내 모델은 대부분 공격 유형에서 해외 모델보다 낮은 안전성을 보였다”며 “또한 해외 모델은 한국어와 영어 안전성 차이가 거의 없었으나 국내 모델은 한국어가 상대적으로 더 안전한 경향을 보여 언어적 편차도 확인됐다”고 밝혔다.
최대선 숭실대 AI안전성연구센터장은 “경쟁력 확보를 위해서는 체계적 평가와 지속적 검증, 이에 필요한 기술 확보가 필수적”이라고 강조했다. 센터는 향후 평가 대상을 에이전틱 AI, 멀티모달 모델, 피지컬 AI 등으로 확장해 국내 모델의 신뢰성을 높이는 연구를 이어간다는 계획이다.
[ⓒ 매일경제 & mk.co.kr, 무단 전재, 재배포 및 AI학습 이용 금지]
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
