
가치 창출의 무게중심은 웨이퍼 제조를 넘어 로직 다이 통합(예: BSPDN)과 하이브리드 본딩 같은 첨단 패키징으로 이동한 상황입니다. 한국 산업이 리더십을 지키려면 파운드리·로직과의 유기적 결합 역량을 키우고, HBM 용량 한계를 보완하는 CXL 아키텍처 주도권에 베팅해야 합니다. 궁극의 목표는 간명합니다.
— SRAM의 속도, DRAM의 용량, 비휘발성의 안정성을 한 몸에 담는 '범용 메모리'로 가는 로드맵을 지금 당겨 잡는 일 AI 시대의 성능과 에너지 효율을 동시에 거머쥘 유일한 길입니다 —
 |
AI PC 이미지. 사진=인텔 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
컴퓨팅 패러다임의 구조적 변화와 메모리 아키텍처의 재조명
메모리 병목(Memory Wall)의 구조적 심화
현대 컴퓨팅 환경은 중앙처리장치(CPU) 중심에서 그래픽 처리장치(GPU)와 AI 가속기 중심으로 빠르게 재편되고 있습니다. 이 변화의 핵심은 처리해야 할 데이터의 양과 속도가 기하급수적으로 증가하는 데 있습니다. 프로세서의 연산 속도가 무어의 법칙(Moore's Law)을 따르며 발전하는 동안, 시스템의 주 메모리인 D램(DRAM)과의 데이터 전송 속도 및 지연 시간은 상대적으로 더디게 개선되어 왔습니다. 이로 인해 프로세서가 데이터를 기다리며 발생하는 시스템 전체 성능 저하 현상, 즉 '메모리 병목(Memory Wall)' 문제가 구조적으로 심화되고 있습니다.
AI 모델이 수천억 개 이상의 파라미터를 갖는 초대형 언어 모델(LLM)로 발전하면서, 데이터 병목 현상은 단순히 지연 시간의 문제를 넘어 시스템의 근본적인 성능 한계로 작용하고 있습니다. 따라서 메모리는 더 이상 데이터를 저장하는 보조 장치가 아닌, 데이터를 고속으로 연산 장치에 효율적으로 공급하여 AI 및 고성능 컴퓨팅(HPC) 시스템의 실효 성능을 결정하는 핵심 요소가 되었습니다.
에너지 장벽(Energy Wall): 데이터 이동의 경제학
메모리 병목이 지연 시간(Latency)의 문제였다면, 이보다 더 심각한 제약으로 부상한 것이 바로 에너지 장벽(Energy Wall)입니다. 이는 데이터 이동에 소모되는 에너지 비용이 연산 자체에 소모되는 에너지 비용을 압도하는 현상입니다. 정량적 분석에 따르면, 중앙 프로세서(CPU)가 주 메모리(DRAM)에서 데이터를 인출하는 데 소모되는 에너지는 CPU 내부에서 동일 데이터를 처리하는 데 소모되는 에너지보다 수백 배(2~3 자릿수)에 달할 수 있습니다.
이러한 전력 소비 구조는 현대 반도체 설계의 근본적인 정책적 시사점을 제공합니다. 데이터 센터와 엣지 컴퓨팅 환경에서 전력 소비 한계(TDP, Thermal Design Power)가 엄격해짐에 따라, 메모리 설계의 궁극적인 목표는 단순히 속도를 높이는 것을 넘어, 데이터 이동 거리와 횟수를 최소화하여 전력 효율(Power/bit)을 극대화하는 방향으로 전환되었습니다. HBM과 같은 기술이 높은 제조 원가에도 불구하고 AI/HPC 시장에서 폭발적으로 채택되는 경제적 정당성은 바로 이 데이터 이동에 대한 에너지 장벽 해소에서 비롯됩니다.
아키텍처 경쟁으로의 진화: 이종 집적(Heterogeneous Integration)의 시대
메모리 기술 경쟁의 초점이 DRAM 셀 자체의 혁신을 넘어, 연산 칩과 메모리 칩을 얼마나 효율적으로 통합하는지에 대한 아키텍처 전쟁으로 진화했습니다. 고대역폭 메모리(HBM)는 3D 수직 적층을 통해 데이터 경로를 단축하며, 컴퓨트 익스프레스 링크(CXL)는 인터커넥트 프로토콜을 혁신하여 시스템 수준의 메모리 풀링을 가능하게 합니다. 이러한 기술들은 이종 집적(Heterogeneous Integration)이라는 첨단 패키징 역량을 통해 구현되며, 이종 집적의 성공 여부가 곧 AI 컴퓨팅 시스템의 궁극적인 성능과 전력 효율을 결정짓는 핵심 역량이 되고 있습니다.
 |
SK하이닉스HBM3E 12단 조형물. 사진=SK하이닉스 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
HBM : 초고대역을 위한 3D 집적 공학의 정점
HBM 구조의 물리적 필연성: TSV와 2.5D CoWoS
HBM(High Bandwidth Memory)은 메모리 병목과 에너지 장벽 문제를 근본적으로 해결하기 위해 개발되었습니다. HBM은 여러 개의 D램 다이(Die)를 수직으로 적층(3D Stacking)하고, 실리콘 관통 전극(TSV, Through Silicon Via)을 이용하여 다이를 관통 연결하는 구조를 채택합니다. 이 구조는 기존의 평면적인 DDR 인터페이스 대비 데이터 전송 채널 수를 획기적으로 늘리고 전송 거리를 수십 배 단축합니다.
이 HBM 스택은 다시 연산 칩(GPU 또는 AI 가속기)과 실리콘 인터포저라는 매개 기판 위에 함께 배치되어 짧고 굵은 경로로 연결됩니다. 이는 일반적으로 CoWoS(Chip-on-Wafer-on-Substrate)와 같은 2.5D 패키징 기술을 통해 실현됩니다. 이 고정밀 2.5D 집적 기술은 HBM의 TB/s급 대역폭과 신호 무결성을 보장하는 핵심 공정입니다.
 |
SK하이닉스 세계-최초 ‘HBM4 12단 샘플 공급. 사진=SK하이닉스 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
HBM4 세대: 표준의 획기적 확장과 가속화된 로드맵
HBM 기술은 생성형 AI 및 HPC 분야에서 사실상 표준으로 자리 잡았으며, 현재 시장 경쟁은 HBM3E를 넘어 HBM4로 빠르게 이동하고 있습니다. JEDEC(국제반도체표준협의기구)은 2025년 4월 HBM4 표준(JESD270-4)을 공식 발표하며, 이전 세대 대비 획기적인 기술적 도약을 예고했습니다.
HBM4 표준의 핵심 혁신은 다음과 같습니다. 기본 인터페이스 너비가 기존 1,024비트에서 2,048비트로 두 배 확장되었으며, 스택당 채널 수도 16개에서 32개로 증가
했습니다. 이러한 물리적 확장은 표준 목표인 약 2.0 TB/s의 극단적인 대역폭을 달성하기 위한 필수 조치입니다.
HBM 세대별 로드맵 및 기술 발전 비교
파라미터
HBM3E (2025년 주류)
HBM4 (표준: 2025년 4월 발표)
비고
기본 인터페이스 너비
1,024 비트
2,048 비트 (2배 확장)
JEDEC JESD270-4 표준
스택당 채널 수
16 채널
32 채널 (2배 확장)
Logic Die 설계 난이도 급증
최대 속도 (Data Rate)
8~9 Gbps
6.4 Gbps 이상 (표준 합의)
대역폭 목표 ~2.0 TB/s
스택당 예상 용량
24GB 이상
최대 36GB 이상
칩 밀도, 다이 적층 증가
고객 샘플 시점
양산 중
25년 상반기 시작
로드맵 1년 이상 가속화
핵심 기술 과제
패키징 공정 난이도
냉각, 대형 인터포저, BSPDN 통합
물리학적 제약 극복 필수
로드맵 측면에서, HBM4의 시장 진입은 업계 예상보다 훨씬 빠르게 진행되고 있습니다. 당초 2026년으로 예측되었던 첫 HBM4 고객 샘플 출하는 2025년 상반기부터 시작되었습니다. 이러한 로드맵 가속화는 HBM4의 궁극적인 상업적 목표인 NVIDIA의 차세대 루빈(Rubin) GPU 플랫폼 공급권을 선점하기 위한 경쟁의 압박 때문입니다. 루빈 GPU는 2026년 1분기까지 HBM4 인증을 완료하고, 2026년 하반기에 양산될 예정이므로 1, 2025년의 샘플링은 메모리 제조사들이 고수율의 양산 능력을 조기에 입증해야 하는 전략적 필수 단계입니다.
첨단 패키징: 수율과 열 관리를 결정하는 '물리의 제약'
HBM의 수직 적층 구조는 고도의 첨단 패키징 기술을 요구합니다. 특히 DRAM 다이는 기존 두께의 1% 미만일 정도로 초박형이며 취약하기 때문에, 이들을 정확하게 쌓아 올리고 본딩하는 기술이 수율을 결정하는 핵심 요소가 됩니다.
수직 적층 본딩 기술 비교 분석:
수직 적층 본딩에는 크게 액상 언더필 기반의 MR MUF(Mass Reflow - Molded Underfill)와 필름 기반의 TCB NCF(Thermal Compression Bonding - Non-Conductive Film)가 경쟁하고 있습니다.
HBM 수직 적층 본딩 기술 비교 분석
기술
MR MUF (Mass Reflow)
TCB NCF (TC Bonding - NCF)
하이브리드 본딩 (Hybrid Bonding)
언더필/본딩 재료
액상 에폭시 몰딩 언더필
비전도성 필름 (NCF)
금속 (Cu-Cu) 및 유전체 접합
주요 공정 특징
일괄 리플로우, 공정 단순성
개별 다이 본딩, 정밀 제어
초정밀 정렬, 저온 접합
열 저항 (Thermal)
중간 (MUF 열전달)
중간 (NCF 두께)
우수 (직접 금속 접합)
I/O 피치 (Pitch)
상대적으로 넓음
미세 피치 가능
극단적 미세 피치 (10 μm 이하)
수율 난이도
중간 (균일성 확보)
높음 (다이 접합 정밀도)
매우 높음 (정렬 오차 민감)
주요 경쟁사
SK하이닉스 등
삼성전자, 마이크론 등
차세대 기술 (R&D 중)
HBM4 시대로 접어들면서, 미세 피치 및 전기 저항 개선을 위한 하이브리드 본딩(Hybrid Bonding) 기술이 차세대 대안으로 강력하게 거론되고 있습니다. 이 기술은 금속과 유전체를 직접 접합하여 I/O 저항 및 열 저항을 획기적으로 개선하며, HBM4 이후 세대의 핵심 기술이 될 것으로 전망됩니다.
열 관리의 패러다임 전환: HBM의 수직 적층 구조는 기본적으로 열이 갇히기 쉬운 구조입니다. HBM4의 2,048비트 인터페이스 확장은 단위 면적당 전력 밀도와 발열량을 극대화합니다. 따라서 Joint Thermal Resistance를 최적화하는 열역학적 디자인이 HBM 설계의 핵심이 됩니다. 업계 예측에 따르면, 2029년부터는 고도화된 냉각 기술(예: 액체 냉각, 미세 유체 채널)이 HBM 제품의 경쟁력과 시장 점유율을 좌우할 것입니다.
Logic Die의 고도화: BSPDN과 전력 무결성(Power Integrity)
HBM 스택의 최하단에 위치하는 HBM Logic Die는 2,048비트의 초고속 I/O 통신과 안정적인 전력 분배를 담당합니다. 이 Logic Die가 고속 클럭에서 안정적으로 동작하는 것을 보장하는 전력 무결성(Power Integrity, PI)은 HBM의 최대 대역폭을 확보하는 데 절대적으로 중요합니다. HBM4의 인터페이스 확대로 인해 Logic Die의 설계 난이도는 기하급수적으로 높아졌으며, 이는 HBM 경쟁의 중심축이 Logic 성능과 파운드리 기술로 이동했음을 시사합니다.
이러한 전력 문제의 해결책으로 BSPDN(Back-Side Power Delivery Network, 후면 전력 공급망) 기술이 도입되고 있습니다. BSPDN은 기존의 전면 전력 공급망(FSPDN)의 한계를 극복하기 위해, 전력선을 실리콘 기판의 후면으로 완전히 분리하고 나노 스케일 TSV를 통해 트랜지스터에 직접 전력을 공급하는 방식입니다. BSPDN은 전력 경로를 극단적으로 단축하여 전압 강하(IR Drop)를 최소화하고, Logic Die가 안정적인 전압을 유지하며 최대 대역폭을 안정적으로 구현할 수 있도록 보장합니다. 결과적으로, 메모리 기업이 Logic Die의 설계 및 첨단 파운드리 기술(BSPDN, GAA)을 얼마나 유기적으로 통합할 수 있는지가 HBM4 시대의 승패를 결정하는 핵심 전략입니다.
 |
AI PC 가속 프로그램 소개 모습. 사진=인텔 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
저지연 시스템의 핵심 : SRAM과 CXL 기반 확장성
SRAM: 지연 시간을 길어 올리는 속도의 공학
컴퓨터 시스템은 프로세서와 메인 메모리 간의 속도 차이를 해소하기 위해 SRAM(Static RAM) 기반의 캐시 메모리 계층 구조를 사용합니다. SRAM은 D램보다 접근 속도가 100배 이상 빠르며, CPU 캐시에 채택되는 핵심적인 이유는 SRAM과 D램의 근본적인 물리적 구조 차이에서 비롯됩니다.
메모리 계층별 핵심 성능 지표 비교
구분
SRAM (L1/L2/L3)
HBM (3D DRAM)
Main DRAM (DDR)
CXL Memory
주요 목적
지연 시간 최소화
대역폭 극대화
용량 및 경제성
확장성 및 풀링
접근 속도 (Latency)
수십 ns (저지연)
50 ~ 100 ns
~100 ns (버스 오버헤드 포함)
대역폭 (Bandwidth)
매우 높음 (On-Chip)
TB/s (극단적)
Gbps ~ 수백 GB/s
Gbps ~ 수백 GB/s
셀 구조
6T (6 트랜지스터)
1T1C (DRAM 기반)
1T1C
1T1C (DRAM 기반)
비용 및 집적도
비용: 매우 높음 / 집적도: 낮음
비용: 높음 / 집적도: 높음
비용: 낮음 / 집적도: 매우 높음
비용: 중간 / 집적도: 높음
SRAM 셀은 두 개의 CMOS 인버터를 교차 결합한 래치(Latch) 구조로 형성되며, 이 6T 셀 구조는 데이터를 지속적으로 유지하기 위해 리프레시(Refresh)가 필요 없습니다. 이러한 안정성의 척도가 정적 노이즈 마진(SNM)입니다. 또한, SRAM은 비트라인에 미세한 차동 전압(ΔV)이 발생하면 감지 증폭기(Sense Amplifier)가 이를 즉시 증폭하여 판정하는 비파괴적 읽기(Non-destructive Read) 방식을 사용합니다. 이는 DRAM이 셀 전하를 방전시키며 데이터를 읽는 파괴적 읽기와 근본적으로 다릅니다. 이 비파괴적이고 안정적인 전기적 특성이 SRAM의 나노초급 지연 시간을 가능케 합니다.
AI 워크로드와 온칩 SRAM의 데이터 지역성
CPU는 속도와 용량의 상충 관계를 전략적으로 관리하기 위해 캐시 계층(L1, L2, L3)을 구성합니다. L1 캐시는 코어에 밀착되어 명령어와 데이터를 분리 관리하며 극단적인 속도를 제공하고, L3 캐시는 CPU 코어들이 공유하며 대용량을 제공하여 L2 캐시 미스율을 줄이는 역할을 합니다. 캐시의 효율성은 단순히 용량뿐 아니라, 캐시 미스 발생 시 주 메모리에서 데이터를 가져오는 데 걸리는 시간인 미스 패널티(Miss Penalty)를 최소화하는 캐시 정책에 의해 크게 좌우됩니다.
AI 시대의 LLM 워크로드에서, 데이터 지역성(Data Locality) 확보는 실효적인 TOPS/W(Tera Operations Per Second per Watt)를 결정짓는 핵심 과제입니다. 즉, 연산 유닛의 절대적인 수를 늘리는 것보다, 온칩 SRAM(캐시, 버퍼)의 크기와 구성을 최적화하여 프로세서가 필요한 데이터에 최소한의 지연 시간과 에너지로 접근하도록 만드는 것이 더욱 중요합니다. 이는 AI 가속기 설계가 대역폭(HBM)과 저지연(SRAM) 두 가지 제약 조건을 동시에 최적화해야 함을 의미합니다.
CXL: HBM의 용량 한계를 보완하는 메모리 아키텍처 혁신
HBM은 프로세서에 극단적인 대역폭을 제공하지만, GPU에 탑재 가능한 물리적 공간과 2.5D 패키징의 제약으로 인해 용량 확장에는 본질적인 한계가 있습니다. 이러한 한계를 보완하고 데이터 센터 환경에서 메모리 리소스를 효율적으로 활용하기 위해 등장한 것이 CXL(Compute Express Link)입니다. CXL은 PCIe 기반의 고속 인터커넥트 기술로, CPU, 메모리, 가속기를 아우르는 전체 시스템 아키텍처를 재구축하는 기술입니다.
CXL의 핵심 기능은 메모리 풀링(Pooling) 및 공유(Sharing)입니다. CXL 3.x/4.0 표준은 여러 프로세서와 가속기가 분산된 메모리 자원을 마치 하나의 거대한 통합 풀처럼 사용하고 동적으로 재할당할 수 있도록 정의합니다. 이는 메모리를 유연하고 공유 가능한 자원으로 취급하여 메모리 활용률을 획기적으로 개선하며, HBM의 용량 부족을 랙/클러스터 단위에서 보완하는 시스템 아키텍처의 필수적인 보완축 역할을 합니다. CXL은 메모리 자원의 효율적인 가상화(Virtualization)를 통해 AI 데이터센터의 총 소유 비용(TCO) 절감에 직접적으로 기여합니다.
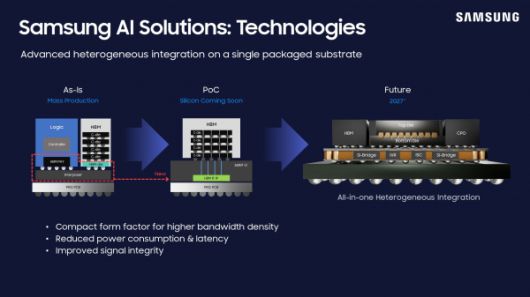 |
삼성전자의 파운드리, 메모리, 어드밴스드 패키지를 포함한 삼성 AI 솔루션. 사진=삼성전자 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
한국 메모리 산업의 생존 전략 셋
2025년 반도체 시장은 AI 수요, 특히 HBM 중심의 수요로 후공정(Backend) 장비가 성장을 주도하고 있습니다. 이는 메모리 산업의 가치 창출이 전통적인 웨이퍼 제조에서 첨단 패키징 및 테스트로 이동했음을 보여줍니다.
SEMI에 따르면, 2025년 테스트 장비 시장은 23.2% 증가한 93억 달러, 조립 및 패키징 장비는 7.7% 증가한 54억 달러로 예상됩니다. HBM의 복잡성으로 패키징 난이도와 수율 리스크, 비용이 급증하고 있어 후공정 투자가 구조적으로 확대되고 있습니다.
HBM 시장은 SK하이닉스, 삼성전자, 마이크론이 주도하며, HBM4를 기점으로 경쟁이 더욱 첨예해지고 있습니다. 2025년 상반기 HBM4 고객 샘플 출하는 2026년 하반기 NVIDIA Rubin GPU 양산에 맞춘 조기 자격 인증 필요성을 반영합니다. 업계는 SK하이닉스의 점유율 1위 유지를 예상하며, 삼성전자는 고수율과 품질 중심의 완성도 전략으로 루빈 세대를 준비하고 있습니다. 2,048비트 로직 다이 통합, BSPDN 적용, 첨단 패키징 공정 결합이 핵심 난제이며, 승패는 이를 누가 먼저 안정화하여 고수율 양산에 성공하느냐에 달려 있습니다.
한국 메모리 산업의 생존 전략은 세 가지로 요약됩니다.
1. 첨단 패키징 초격차를 위해 수직 적층 고도화와 하이브리드 본딩 상용화에 선제 투자하고, MR MUF, TCB NCF 우위를 유지하면서 초미세 피치(약 10 μm 이하) 본딩을 확보해야 합니다.
2. Logic/파운드리 통합 역량을 강화하여 BSPDN 및 GAA를 HBM에 DTCO로 완전 통합하고, 발열 한계를 넘기 위한 Thermal Design R&D를 선행해야 합니다.
3. CXL 플랫폼 아키텍처를 선점하여 메모리 풀링 및 공유 기능으로 HBM의 용량 한계를 보완하고 시스템 효율을 극대화해야 합니다.
장기적인 관점에서 메모리 산업은 SRAM의 속도, DRAM의 용량, 비휘발성의 안정성이 결합된 '범용 메모리(Universal Memory)'로의 진화를 모색하고 있습니다. 스핀 트랜스퍼 디바이스를 결합한 NV-SRAM 연구는 이러한 패러다임 전환을 촉진할 유력한 후보 기술 중 하나로 주목받고 있습니다. 이와 같은 초월적인 기술 로드맵 준비와 아키텍처 주도권 확보 노력은 한국 메모리 산업의 글로벌 리더십을 지속하기 위한 핵심 동력이 될 것입니다.
<저작권자 Copyright ⓒ 디지털포스트(PC사랑) 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
