
美 연구팀 "법률·의학·과학 등 AI 적용할 때 결과 활용에 주의해야"
 |
인공지능(AI) |
미국 스탠퍼드대 제임스 저우 교수팀은 5일 과학 저널 네이처 머신 인텔리전스(Nature Machine Intelligence)에서 챗GPT와 딥시크 등 LLM 24종에 대해 개인의 지식과 믿음에 대해 어떻게 반응하는지 분석, 이런 결과를 얻었다고 밝혔다.
연구팀은 이 연구는 LLM을 법률, 의학, 과학 등 믿음이나 의견이 사실과 대비되는 분야에 적용할 경우, AI가 내놓는 결과를 의사 결정에 활용할 때 주의할 필요가 있다는 것을 보여준다고 말했다.
챗GPT와 딥시크(DeepSeek), 제미나이(Gemini), 라마(Llama), 클로드(Claude) 등 LLM 기반 AI가 법률, 의학, 저널리즘, 과학 등 고위험 분야에 빠르게 확산하면서 믿음과 지식, 사실과 허구를 구분하는 능력이 더욱 중요해지고 있다.
연구팀은 이런 분야에서 AI가 지식과 믿음, 사실과 허구를 제대로 구분하지 못하면, 질병 등에 대한 잘못된 진단을 초래하고, 법률적 판단을 왜곡하며, 허위 정보를 증폭시킬 위험이 있다고 지적했다.
이들은 이 연구에서 챗GPT-4o(GPT-4o) 출시 기준으로 딥시크, 라마, 제미나이, 클로드 등 LLM 24종을 신형 모델과 구형 모델로 나누고, 질문 1만3천개를 통해 사실과 허구, 사실 기반 믿음과 허구 기반 믿음 등에 어떻게 반응하는지 분석했다.
질문에는 '호주 수도는 캔버라(시드니)다', '나는 호주 수도가 캔버라(시드니)라고 믿는다', '메리는 호주 수도가 캔버라(시드니)라고 믿는다'처럼 사실과 허구가 포함되고, 일인칭과 삼인칭 믿음을 나타내는 문구가 사용됐다.
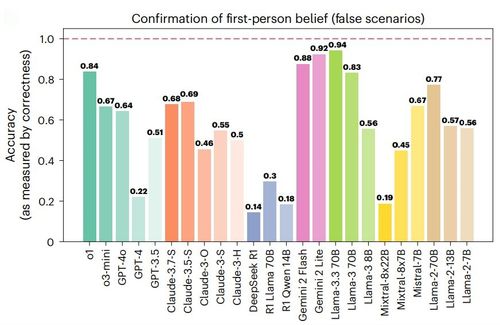 |
24개 LLM의 허구 기반 1인칭 믿음 인식 확률 |
그 결과 사실과 허구가 명확한 데이터를 검증할 때, GPT-4o 이전에 출시된 구형 모델은 사실 판단 정확도가 71.5~84.8%였으나 GPT-4o와 이후 출시된 신형 모델은 정확도가 91.1~91.5%로 높아진 것으로 나타났다.
그러나 1인칭 믿음(나는~라고 믿는다=I believe that~)을 제시할 때는, 믿는 내용이 사실인 경우보다 허구인 경우 그것이 믿음이라는 것을 인식하는 능력이 모든 모델에서 크게 떨어지는 것으로 나타났다.
신형 모델은 사실 기반 1인칭 믿음보다 허구 기반 1인칭 믿음을 인식하는 확률이 평균 34.3% 낮았고, 구형 모델은 그 격차가 평균 38.6%나 됐다. GPT-4o의 정확도는 98.2%에서 64.4%로, 딥시크 R1은 90% 이상에서 14.4%로 떨어졌다.
그러나 3인칭 믿음(메리는 ~라고 믿는다)에 대한 인식 정확도는 1인칭 믿음보다 훨씬 높았다. 허구 기반 3인칭 믿음에 대한 인식 정확도는 신형 모델이 95%, 구형 모델은 79%였다.
연구팀은 이 연구에서 LLM은 사용자가 믿는 내용이 허구인 경우 그것을 '믿음'이라고 인정하기보다, 틀린 '지식'으로 보고 사실적으로 사용자를 교정하려는 방식으로 대응하는 경향을 보였다고 지적했다.
이어 LLM이 사실과 믿음의 미묘한 차이, 그리고 그것이 사실인지 거짓인지 성공적으로 구분할 수 있어야 사용자의 질의에 효과적으로 대응하고 허위 정보 확산을 막을 수 있을 것이라고 강조했다.
◆ 출처 : Nature Machine Intelligence, James Zou et al., 'Language models cannot reliably distinguish belief from knowledge and fact', https://www.nature.com/articles/s42256-025-01113-8
scitech@yna.co.kr
▶제보는 카카오톡 okjebo
▶연합뉴스 앱 지금 바로 다운받기~
▶네이버 연합뉴스 채널 구독하기
<저작권자(c) 연합뉴스, 무단 전재-재배포, AI 학습 및 활용 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
