
 |
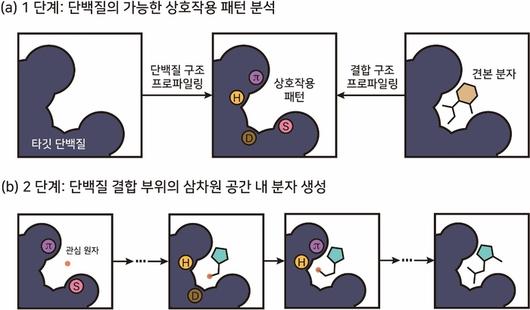
KAIST가 개발한 단백질-분자 상호작용 패턴 기반 3차원 생성형 AI 개념도 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
최근 자연어나 이미지, 동영상, 음악 등 다양한 분야에서 주목받는 생성형 AI가 신약 설계 분야에서도 기존 신규성 문제를 극복하고 새로운 혁신을 일으키고 있다.
한국과학기술원(KAIST·총장 이광형)은 김우연 화학과 교수팀이 단백질-분자 사이 상호작용을 고려해 활성 데이터 없이 타겟 단백질에 적합한 약물 설계 생성형 AI를 개발했다고 18일 밝혔다.
신규 약물을 발굴하려면 질병 원인이 되는 타겟 단백질에 특이적으로 결합하는 분자를 찾는 것이 중요하다.
기존 약물 설계 생성형 AI는 특정 단백질의 이미 알려진 활성 데이터를 학습에 활용해 기존 약물과 유사한 약물을 설계하려는 경향이 있다.
이는 신규성이 중요한 신약 개발 분야에서 치명적인 약점으로 지적돼 왔다. 또 사업성이 높은 계열 내 최초(First-in-class) 타겟 단백질에 대해서는 실험 데이터가 매우 적거나 전무한데, 이 경우 기존 방식의 생성형 AI를 활용하는 것이 불가능하다.
연구팀은 이런 데이터 의존성 문제를 극복하기 위해 단백질 구조 정보만으로 분자를 설계하는 기술 개발에 주목했다.
타겟 단백질 약물 결합 부위에 대한 3차원 구조 정보를 주형처럼 활용해 해당 결합 부위에 꼭 맞는 분자를 주조하듯 설계하는 것이다. 마치 자물쇠에 딱 맞는 열쇠를 설계하는 것과 같은 이치다.
또 기존 단백질 구조 기반 3차원 생성형 AI 모델들은 신규 단백질에 대해 설계한 분자 안정성과 결합력이 떨어지는 등 낮은 일반화 성능을 개선하기 위해서 연구팀은 신규 단백질에 대해서도 안정적으로 결합할 수 있는 분자를 설계할 수 있는 기술을 개발하는데 초점을 뒀다.
연구팀은 설계 분자가 단백질과 안정적으로 결합하기 위해서는 단백질-분자 간 상호작용 패턴이 핵심 역할을 하는 것에 착안했다.
연구팀은 생성형 AI가 이런 상호작용 패턴을 학습하고, 분자 설계에 직접 활용할 수 있도록 모델을 설계하고 재현할 수 있도록 학습시켰다.
기존 단백질 구조 기반 생성형 AI 모델들은 부족한 학습 데이터를 보완하기 위해 10만~1000만 개 가상 데이터를 활용하는 반면, 이번 연구에서 개발한 모델의 장점은 수천 개의 실제 실험 구조만을 학습해도 월등히 높은 성능을 발휘한다는 것이다.
이는 자연에서 관찰되는 단백질-분자 상호작용 패턴을 사전 지식의 형태로 학습에 활용함으로써 적은 데이터만으로도 일반화 성능을 획기적으로 높인 것에 기인한다.
일례로 아시아인에 주로 발견되는 돌연변이 상피 성장인자 수용체(EGFR-mutant)는 비소세포폐암의 주요 원인으로 알려져 있는데, 이를 타겟으로 하는 약물을 설계하기 위해서는 야생형(wild-type) 수용체에 대한 높은 선택성을 고려하는 것이 필수적이다.
연구진은 생성형 AI를 통해 돌연변이가 일어난 아미노산에 특이적인 상호작용을 유도해 분자를 설계했고, 그 결과 생성된 분자의 23%가 이론상으로 100배 이상의 선택성을 가지는 것으로 예측됐다.
이와 같은 상호작용 패턴에 기반한 생성형 AI는 인산화효소 저해제 등과 같이 약물 설계에 있어 선택성이 중요한 상황에서 더욱 효과적으로 활용될 수 있다.
제1 저자로 참여한 KAIST 화학과 정원호 박사과정 학생은 “사전 지식을 인공지능 모델에 사용하는 전략은 상대적으로 데이터가 적은 과학 분야에서 적극적으로 사용되어 왔다”며 “이번 연구에서 사용한 분자 간 상호작용 정보는 약물 분자뿐 아니라 다양한 생체 분자를 다루는 바이오 분야의 문제에도 유용하게 적용될 수 있을 것”이라고 말했다.
한국연구재단의 지원을 받아 수행된 이번 연구는 국제 학술지 '네이처 커뮤니케이션즈' 3월 15호에 게재됐다.
김영준 기자 kyj85@etnews.com
[Copyright © 전자신문. 무단전재-재배포금지]
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
