
 |
(사진=셔터스톡) |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
메타가 '라마3'를 기반으로 구축한 최초의 이미지-텍스트 멀티모달 모델을 공개했다. 벤치마크에서 크기가 100배 이상인 'GPT-4V' '제미나이 울트라' '클로드 3 오퍼스'와 비슷한 성능을 기록했다고 밝혔다.
마크테크포스트는 31일(현지시간) 메타가 80억 매개변수의 '라마3 8B' 모델을 기반으로 시각적 정보를 이해하는 비전 모델 '라마3-V'를 출시했다고 보도했다.
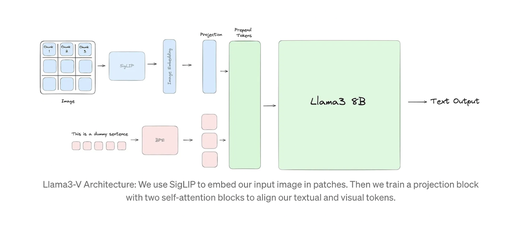
라마3-V는 멀티모달 이해를 위해 기존 라마3 8B에 비전 인코더인 '시그립(SigLiP)' 모델을 도입했다. 시그립 모델은 입력 이미지를 가져와 일련의 시각적 토큰으로 인코딩한다. 이런 시각적 토큰은 텍스트를 처리하는 임베딩 모델을 거쳐 텍스트 토큰과 결합, 라마3 8B 모델에 전달된다.
시그립의 비전 인코더는 이미지를 겹치지 않는 패치로 나누고 이를 저차원의 임베딩 공간으로 투영, 고차원 특징 추출을 위해 셀프 어텐션을 적용한다. 시그립의 이미지 임베딩을 텍스트 임베딩과 정렬하기 위해서 두개의 셀프 어텐션 블록이 있는 프로젝션 모듈을 사용한다. 이런 임베딩에서 생성된 시각적 토큰은 텍스트 토큰 앞에 추가돼 라마3를 위한 '결합 입력(prepend tokens)'을 생성한다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
라마3-V는 다양한 양식이 입력되면 이를 텍스트나 이미지를 처리하는 개별 모델로 인코딩한 뒤 추론을 위해 인코딩을 융합하는 '후기 융합(late fusion)' 방식을 사용하는 멀티모달 모델이다. 다른 양식으로 훈련한 모델들을 연결, 이미지 및 코드와 같은 다른 양식을 텍스트로 변환한 후 다시 토큰으로 변환하는 식이다.
이에 반해 메타가 최근 공개한 멀티모달 모델 '카멜레온'은 처음부터 단일 모델에서 이미지, 텍스트, 코드 등 다중 양식이 혼합된 데이터로 훈련하는 '초기 융합(early-fusion)' 방식을 사용한다.
후기 융합 방식도 잘 작동하는 편이지만, 모델이 양식 간의 정보를 통합하고 이미지와 텍스트가 혼합된 시퀀스를 생성하는 능력이 제한되는 약점이 있다.
그러나 메타는 라마3-V가 시그립 모델을 분리함으로써 이미지 임베딩을 미리 계산하는 캐싱 메카니즘을 통해 메모리 부족 오류를 일으키지 않고 GPU 활용도를 높일 수 있었다고 밝혔다.
또 시그립은 크기가 작기 때문에 리소스를 효율적으로 관리하고 GPU 사용량을 최대화하여 훈련 및 추론 시간을 절약한다고 주장했다. 그 결과 라마-3V 훈련에는 고작 500달러 미만의 비용이 들었다고 말했다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
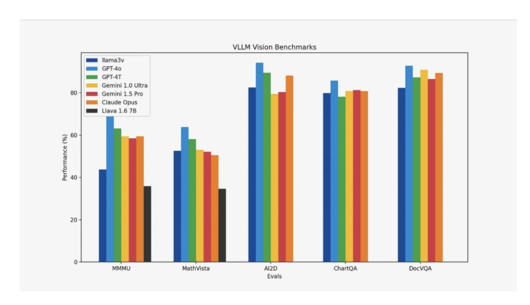
한편 벤치마크에서는 라마3-V가 현재 오픈 소스 SOTA(State-of-the-art, 최고 수준) 비전 언어 모델인 '라바(Llava)'에 비해 10~20% 향상된 성능을 기록했다.
연구진은 또 MMMU를 제외한 대부분의 측정 항목에서 GPT-4V, 제미나이 울트라, 클로드 3 오퍼스와 같이 크기가 100배 이상 큰 폐쇄형 모델과 비슷한 성능을 기록, 작은 크기에도 불구하고 효율성과 경쟁력을 보여줬다고 강조했다.
메타는 이 모델을 깃허브를 통해 오픈 소스로 공개했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
