
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
단일 지식 소스를 기반으로 검색을 실시하는 기존의 검색 증강 생성(RAG)을 넘어, 다양한 도구를 활용해 여러 지식 소스에서 정보를 추출하는 일명 'RAG 에이전트'가 대세가 될 것이라는 전망이 등장했다.
벡터 데이터베이스 회사 위비에이트(Weaviate)는 13일(현지시간) RAG 에이전트가 대형언어모델(LLM) 기반 애플리케이션에서 기업의 '게임 체인저'가 될 것으로 전망한다는 블로그 게시물을 소개했다.
기본적인 RAG 파이프라인은 두가지 주요 요소인 '리트리버(retriever)'와 '제너레이터(generator)'로 구성된다.
리트리버는 벡터 데이터베이스와 임베딩 모델을 사용해 사용자 질문을 분석하고, 인덱싱된 문서에서 가장 유사한 내용을 찾아낸다. 제너레이터는 검색된 데이터를 바탕으로 LLM을 사용해 관련 비즈니스 문맥을 반영한 답변을 생성한다.
이 아키텍처는 기업에 정확한 답변을 제공하는 데 유용하지만, 두개 이상의 정보 소스를 활용해야 할 때에는 한계가 있다.
기존 RAG 파이프라인은 단일 지식 소스를 넘어서는 정보를 제공할 수 없으며, 이로 인해 특정 애플리케이션에만 적용될 수 있다. 또 리트리버가 가져온 정보는 모델의 답변의 기초가 되기 때문에 잘못된 출처는 정확성에 영향을 미칠 수 있다.
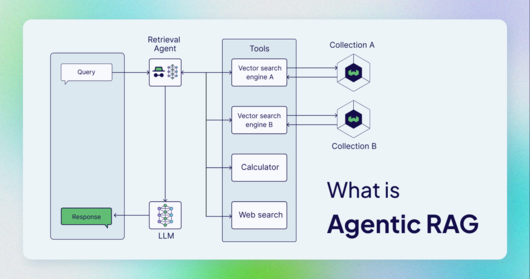
이를 해결하는 방법 중 하나가 바로 AI 에이전트(agentic AI)다. AI 에이;전트는 메모리와 추론 기능을 갖춘 LLM 기반의 AI 에이전트가 여러 단계의 작업을 계획하고, 다양한 외부 도구를 사용해 복잡한 작업을 수행하는 방식이다.
RAG 파이프라인의 리트리버 구성 요소에 적용될 수 있으며, 이를 통해 웹 검색과, 계산기, 다양한 소프트웨어 API를 활용해 단일 지식 소스 이상의 정보를 검색할 수 있다. 사용자의 질문에 맞는 도구를 선택하고, 관련성 있는 정보가 있는지 확인하며, 필요시 재검색을 통해 정확한 정보를 추출한 뒤 제너레이터로 전달해 최종 답변을 생성한다.
이 방식은 LLM 애플리케이션의 지식 기반을 확장시켜 복잡한 질문에도 더 정확하고 검증된 응답을 제공한다. 예를 들어, 벡터 데이터베이스에 지원 내용이 저장된 경우, 사용자가 "오늘 가장 자주 제기된 문제는 무엇인가"라는 질문을 하면, RAG 에이전트는 웹 검색을 통해 오늘 날짜를 확인하고, 그 정보를 벡터 데이터베이스의 정보와 결합해 완전한 답변을 제공할 수 있다.
도구 사용이 가능한 AI 에이전트를 추가함으로써 검색 에이전트는 특정 지식 소스로 질문을 라우팅할 수 있고, 검색된 정보는 처리 전에 검증할 수 있는 계층을 추가할 수 있다. 이로 인해 RAG 에이전트 파이프라인은 정확한 응답을 제공할 수 있다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
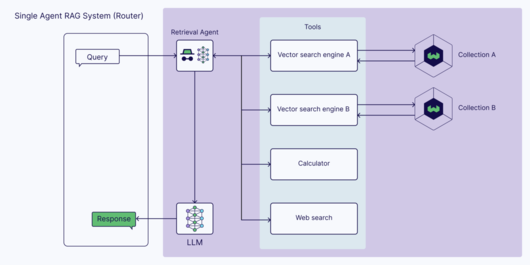
RAG 에이전트 파이프라인을 설정하는 방법으로는 두가지를 소개했다.
하나는 단일 에이전트 시스템으로, 여러 지식 소스를 통해 데이터를 검색하고 검증하는 방식이다. 다른 방법은 다중 에이전트 시스템으로, 여러 특화된 에이전트들이 각각의 지식 소스에서 데이터를 검색하고, 마스터 에이전트가 이 정보를 처리해 제너레이터로 전달하는 방식이다.
하지만 RAG 에이전트는 다단계 처리로 인해 지연 시간이 발생할 수 있다고 지적했다. 또 더 많은 요청을 할수록 계산 비용이 증가할 수 있다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
