
스카우트·매버릭 모델 오픈소스 제공…최상위 모델 '베헤모스'도 소개
전문가 혼합(MoE) 구조 적용…연산 자원 최소화로 작업 효율 극대화
 |
[파리=AP/뉴시스]2023년 6월 프랑스 파리에서 열린 비바테크쇼에 걸린 메타 로고 모습. |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
[서울=뉴시스]윤현성 기자 = 메타가 1년 만에 자사의 인공지능(AI) 거대언어모델(LLM) 시리즈 신작인 '라마4(LLaMA4)'를 공개했다. 최근 중국발 딥시크 쇼크로 인해 AI의 비용 절감 문제가 화두로 떠오른 만큼 전문가 혼합(MoE) 구조를 적용해 연산 효율을 크게 높였다.
메타는 5일(현지 시간) 자사 공식 블로그를 통해 라마4 라인업 중 '스카우트(Scout)'와 '매버릭(Maverick)'을 선보인다고 밝혔다. 이들 두 모델은 오픈소스 형태로 제공된다
가장 강력한 성능을 가진 최상위 모델인 '베헤모스(Behemoth)'도 소개했다. 다만 베헤모스는 아직 개발, 학습을 진행 중으로 오픈 소스 제공 여부도 알려지지 않았다.
메타에 따르면 라마4는 텍스트, 이미지, 음성, 동영상 등을 동시에 이해하는 '멀티모달 AI'다. 기존에 존재하던 LLM보다 연산 효율을 크게 높였다. 메타는 스카우트와 매버릭이 기존의 자사 AI 모델 중 가장 많이 개선됐고, 동급의 AI와 비교해도 멀티모달 기능에서 가장 뛰어나다고 자신했다.
스카우트의 경우 긴 컨텍스트 윈도우를 처리할 수 있어 장문 이해 등에 특화돼있다. 특히 총 1090억개의 매개변수(파라미터)를 보유하고 있지만 실제 작업 시에는 170억개의 매개변수만 활성화돼 더 빠르고 효율적으로 결과를 낼 수 있다.
메타는 스카우트가 젬마3, 제미나이 2.0 플래시 라이트, 미스트랄 3.1 등보다 주요 벤치마크에서 더 나은 결과를 냈다고 강조했다.
매버릭은 보다 복잡한 지시를 수행하는 데 특화돼있다. 매버릭 또한 4000억개의 매개변수를 갖고 있지만 실제 기능을 수행할 땐 170억개의 매개변수만 선택적으로 사용한다. 여타 AI 모델보다 훨씬 더 큰 규모의 모델이지만 매개변수를 선택적으로 활용해 연산 비용은 낮추고 속도는 높이는 '맞춤형' 처리를 가능케 하는 셈이다.
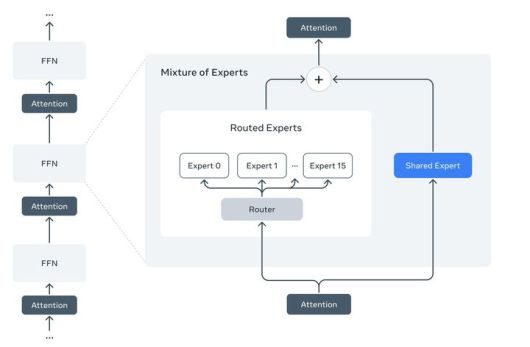 |
메타의 새로운 거대언어모델(LLM) '라마4'의 연산 효율을 크게 높여주는 전문가 혼합(MoE) 구조. (사진=메타 블로그) *재판매 및 DB 금지 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
이같은 비용 효율화는 라마4에 적용된 전문가 혼합 구조 덕분이다. 매버릭의 경우 AI 모델을 128개의 전문가 그룹으로 나누고, 스카우트는 16개의 그룹으로 나눠서 작동한다.
이렇게 나뉜 그룹 중 특정 작업에 맞는 소수의 전문가 경로만 작동하게 하는 식이다. 이를 통해 기존 LLM이 전체 파라미터를 모두 돌려야 했던 것과 달리 성능은 유지하면서도 연산 비용과 에너지 소모는 크게 줄일 수 있게 됐다.
실제로 메타는 매버릭이 GPT-4o나 제미나이 2.0 플래시 등 경쟁작 성능을 제쳤으며, 딥시크 v3와 유사한 성능을 보이면서 능동 매개변수의 절반 이하로 추론 및 코딩 분야에서 비슷한 성과를 냈다고 강조했다.
현재 개발 중인 베헤모스는 메타가 세계에서 가장 똑똑한 AI로 만들고자 학습을 진행하고 있다. 전체 매개변수는 총 2조개에 달하며, 작업 시에는 이 가운데 2880억개가 활성화되는 초거대 모델이다. 메타는 베헤모스가 GPT-4.5, 클로드 소네트 3.7, 제미나이 2.0 프로 등을 능가한다고 밝혔다.
스카우트와 매버릭은 메타 공식 웹사이트와 허깅 페이스 등을 통해 오픈소스로 제공된다. 향후 와츠앱, 페이스북 메신저, 인스타그램 등 AI 어시스턴트에도 순차 적용될 예정이다.
이외에도 메타는 주요 LLM이 지적받는 정치적, 사회적 편향 문제도 라마4에서 크게 줄였다고 설명하기도 했다. 라마4가 특정 정치·사회적 견해를 우선하지 않도록 하고, 다양한 관점에 중립적으로 답할 수 있도록 반응성을 계속 높이고 있다는 것이다.
라마4는 논쟁의 여지가 있는 정치·사회 주제에 대한 질문도 피하지 않고 답할 예정이다. 논쟁적 질문에 대한 라마 3.3의 거부율은 7%였으나 이를 2% 수준까지 낮췄다.
마크 저커버그 메타 CEO는 자신의 인스타그램을 통해 "우리의 목표는 세계 최고의 AI를 구축하고 이를 오픈 소스로 제공하여 전 세계 모든 사람이 혜택을 누리도록 하는 것"이라며 "라마4는 시작에 불과하며, 앞으로 더 많은 계획이 있다"고 말했다.
☞공감언론 뉴시스 hsyhs@newsis.com
▶ 네이버에서 뉴시스 구독하기
▶ K-Artprice, 유명 미술작품 가격 공개
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
