
챗GPT·나노바나나, 저작권 논란 불거져
정보통신기술協, 생성형 AI 학습 과정 검증
벡터 유사도 기반 콘텐츠 지침 표준화
"AI의 악의적 활용 방지"
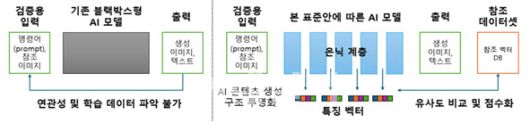 |
특정 벡터 유사도 기반 AI 생성 콘텐츠 검증 시스템 적용 전(좌), 후(우) |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
한국정보통신기술협회(TTA)는 생성형 AI의 학습·생성 과정을 검증하기 위한 벡터 유사도 기반 콘텐츠 검증 지침을 표준화한다고 27일 밝혔다. 이 표준은 검증의 기준이 되는 ‘참조 데이터셋’과 분석 대상인 ‘AI 생성 콘텐츠’에서 각각 특징 벡터를 추출해 비교하는 방식을 제시한다.
참조 데이터는 작가별 그림체 또는 선정적·폭력적 콘텐츠 등 검증에 활용 가능한 유사 데이터로 구성한다. 이 참조 데이터셋에서 특징 벡터를 추출해 참조 벡터 데이터베이스(DB)에 등록하고, AI의 콘텐츠 생성 과정에서 생성되는 특징 벡터와 코사인 유사도를 계산한다. 이때, 유사도가 임계값을 초과하면, 해당 콘텐츠가 참조 데이터셋의 영향을 받아 생성된 것이라고 판단한다. 이를 통해 저작권 분쟁 발생 시에는 AI 생성 콘텐츠가 특정 작가의 작품을 무단 학습했는지를 입증하는 근거 등으로 활용할 수 있다. 또한, 유사도가 높은 참조 데이터가 선정적·폭력적 콘텐츠인 경우에는 유해 콘텐츠로 판단하고 사전에 차단할 수 있다.
앞서 올 상반기 지브리, 심슨 가족 등 유명 애니메이션 화풍을 모방한 프로필 이미지 생성이 유행했다. 당시 일부 앱에서 의도치 않은 유해 콘텐츠가 생성되는 등 기술 오·남용되는 사례들이 보고되면서 딥페이크 등 심각한 사회적 문제로 이어질 수 있다는 우려가 나왔다. 생성형 AI는 방대한 딥러닝 모델을 통해 학습·생성 과정을 내부적으로 처리하기 때문에, 부적절한 데이터가 학습에 쓰여도 이를 추적·통제하기 어렵기 때문이다.
한편 이번 표준은 한국전자기술연구원, 다차원영상기술표준화포럼이 제안 문화체육관광부 ‘악의적 활용을 차단하는 생성형 AI 모델을 탑재한 콘텐츠 창작 및 공유 플랫폼 기술 개발’, ‘저작권 보호를 위한 멀티모달 생성형 AI 모델의 데이터셋 저작권 판별 기술’ 과제의 일환으로 제안됐다.
TTA는 이번 콘텐츠 검증 지침을 연내 제정 목표로 추진 중이다. 앞서 TTA는 불법촬영 음란영상물 필터링을 위한 특징 데이터베이스 제작 지침 등 디지털 콘텐츠 관련 200여 건의 표준을 제정한 바 있다.
손승현 TTA 회장은 “AI가 학습하는 데이터와 생성하는 콘텐츠는 디지털 사회의 핵심 자원이자 중요한 비즈니스 모델이 될 것”이라며 “TTA는 AI의 악의적 활용을 방지하고 안전한 디지털 콘텐츠 생태계 조성에 앞장서겠다”고 말했다.
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
