
규모가 큰 기업이 소수의 애플리케이션만 사용하는 경우는 거의 없다. 대기업은 수천 가지 애플리케이션을 사용하며, 코드 라인 수로 따지면 수십억 라인에 달한다. 이런 코드베이스에는 수십 년 동안 누적된 프레임워크와 라이브러리, 그리고 늘 변화하는 베스트 프랙티스가 반영돼 있다. 결과적으로 오래된 API, 일관성 없는 규칙, 배포와 보안을 위험에 빠트리는 취약점이 발생한다.
수동 리팩터링은 이와 같은 환경에서는 확장되지 않는다. 이 문제를 해결하기 위해 등장한 것이 바로 오픈리라이트(OpenRewrite)다.
오픈리라이트는 개발자를 위해 안전하고 결정론적인 현대화를 가능하게 해주는 오픈소스 자동 리팩터링 프레임워크로, 다음과 같은 두 가지 핵심 축을 기반으로 한다.
- - 무손실 시맨틱 트리(Lossless Semantic Tree, LST) : 정확하고 풍부한 소스 코드 데이터 표현
- - 레시피 : 변환을 수행하는 모듈형의 결정론적 프로그램
이 두 가지 축이 함께 반복, 감사, 확장 가능한 애플리케이션 현대화를 위한 기반을 제공한다.
무손실 시맨틱 트리 : 컴파일러보다 더 많은 정보
대부분의 자동 리팩터링 툴은 기본적인 텍스트 패턴이나 추상 구문 트리(Abstract Syntax Trees, AST)를 기반으로 작동한다. AST는 컴파일러의 중추지만 현대화에는 맞지 않는다. AST는 주석, 공백, 서식을 제거하며, 메서드 오버로드, 제네릭 또는 클래스 경로 전반의 종속성을 확인하지 않는다. 코드가 무엇을 말하는지는 알려주지만 그 말이 무슨 의미인지는 알려주지 않으므로 결과적으로 컨텍스트가 빠지고 서식이 손상되거나 사라지고 코드의 실제 의미에 대한 잘못된 추론과 같은 문제가 발생하게 된다.
무손실 시맨틱 트리를 사용하는 오픈리라이트의 접근 방법은 이것과는 근본적으로 다르다. 다음 예시 코드를 보자.
import org.apache.log4j.Logger; import com.mycompany.Logger; // Custom Logger class public class UserService { private static final Logger log = Logger.getLogger(UserService.class); private com.mycompany.Logger auditLog = new com.mycompany.Logger(); public void processUser() { log.info("Processing user"); // log4j - should be migrated auditLog.info("User processed"); // custom - should NOT be migrated } }텍스트 기반 툴은 Log4j에서 SLF4J로 마이그레이션을 시도할 때 log.info() 호출을 찾아서 바꿀 수 있는데, 각 로거를 구분하지는 못한다. 그 결과 예를 들어 그대로 둬야 할 맞춤형 로거를 바꿀 대상으로 파악하거나 info() 메서드가 있는 다른 클래스를 놓치는 등 여기저기서 오탐지가 발생하게 된다.
AST는 텍스트 패턴보다는 코드 구조에 대한 이해도가 높아서, 예를 들어 메서드 호출과 문자열 리터럴을 구분할 수 있다. 그러나 AST도 각 변수가 실제로 어느 Logger 클래스를 참조하는지, 또는 각 log.info() 호출의 실제 타입이 무엇인지는 알 수 없다. 의미 정보가 부족하기도 하고, AST가 모든 서식과 공백, 주석을 제거하기 때문이다.
LST는 어떻게 다르게 작동하는가
LST는 중요한 모든 요소를 보존하면서 완전한 의미 이해까지 더함으로써 이 문제를 해결한다. 모든 주석은 원래 위치에 그대로 유지되고 서식과 들여쓰기, 공백도 유지된다. 변경되지 않은 코드는 완전히 동일하게 유지되므로 풀 요청과 커밋 비교 결과(diff)가 깔끔하게 표시된다.
또한 LST는 다음을 포함해 코드베이스 전체에서 타입을 확인한다.
- - 메서드 오버로드(어느
findById메서드가 실제 호출되는가?) - - 제네릭 매개변수(
List내에 있는 타입은 무엇인가?) - - 상속 관계(이 객체에서 사용 가능한 메서드는 무엇인가?)
- - 모듈 간 종속성(다른 JAR 파일에 정의된 타입)
이 의미 이해 덕분에 비교적 단순한 툴로는 달성할 수 없는 수준의 정밀한 동작이 가능하다. 예를 들어 다음 예시에서 레시피는 java.util.List를 대상으로 작동할 때 첫 라인만 수정한다. 즉, 오탐지가 없다.
import java.util.List; import com.mycompany.List; // Custom List class private List data; // LST knows this is java.util.List private com.mycompany.List items; // LST knows this is the custom class 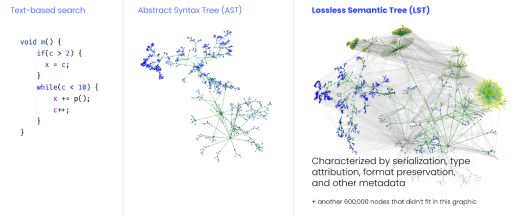 |
Moderne |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
레시피 : 결정론적 코드 변환
LST를 기반 모델로 하는 레시피는 변경을 위한 메커니즘을 제공한다. 레시피는 LST를 탐색하면서 패턴을 찾고 변환을 적용하는 프로그램이다. LST를 위한 질의 언어라고 할 수 있다.
임시 스크립트나 확률론적 AI 제안과 구분되는 레시피만의 특징은 다음과 같다.
- - 결정론적 : 동일한 입력은 항상 동일한 출력을 생성한다.
- - 반복 가능 : 리포지토리가 한 개든 수천 개든 적용이 가능하다.
- - 조합 가능 : 여러 작은 레시피를 큰 플레이북으로 조합할 수 있다.
- - 감사 가능 : 버전 관리, 테스트, 검토가 가능하다.
- - 멱등성 : 몇 번 실행하든 결과는 동일하다.
- - 검증됨 : 활발한 오픈소스 커뮤니티에 의해 수천 개의 공개 코드 리포지토리에서 수시로 검증된다.
오픈리라이트 레시피 구조
오픈리라이트는 레시피 작성을 위해 크게 두 가지 접근 방법을 지원한다. 각 방법은 서로 다른 유형의 변환에 적합하다.
선언적 레시피. 대부분 레시피는 YAML 구성을 사용해 선언적으로 작성된다. 자바 프로그래밍 지식이 없어도 쉽게 작성하고 읽고 유지 관리할 수 있다. 보통 오픈리라이트 레시피 카탈로그에 포함된 기존 레시피를 가리키는데, 이 카탈로그에는 일반적인 프레임워크와 라이브러리를 위한 수백 개의 사전 구축된 변환이 포함돼 있다. 또는 여러 개의 맞춤형 레시피를 조합하는 것도 가능하다.
선언적 레시피는 하나의 레시피를 참조하는 간단한 경우도 있고, 전체 마이그레이션을 조율하는 복잡한 형태도 있다. 다음은 비교적 간단한 부분 마이그레이션 예시다.
type: specs.openrewrite.org/v1beta/recipename: com.example.MigrateToJUnit5displayName: Migrate from JUnit 4 to JUnit 5recipeList: - org.openrewrite.java.ChangeType: oldFullyQualifiedTypeName: org.junit.Test newFullyQualifiedTypeName: org.junit.jupiter.api.Test - org.openrewrite.java.ChangeType: oldFullyQualifiedTypeName: org.junit.Assert newFullyQualifiedTypeName: org.junit.jupiter.api.Assertions - org.openrewrite.maven.AddDependency: groupId: org.junit.jupiter artifactId: junit-jupiter version: 5.8.2명령형 레시피. 맞춤형 로직이 필요한 복잡한 변환의 경우 레시피를 자바 프로그램으로 작성할 수 있다. 이러한 명령형 레시피는 개발자에게 변환 프로세스에 대한 완전한 통제 권한과 전체 LST 구조에 대한 액세스 권한을 부여한다.
레시피 실행은 잘 알려진 컴퓨터 과학 패턴인 방문자 패턴을 사용한다. 그러나 여기서 중요한 부분은 레시피가 소스 코드를 직접 방문하는 것이 아니라 LST 표현을 방문한다는 점이다.
프로세스는 다음과 같다.
- - 소스 코드가 LST로 파싱된다(전체 의미 정보 포함).
- - 방문자가 LST 노드를 체계적으로 탐색한다.
- - 변환 작업에서 LST 구조가 수정된다.
- - LST가 다시 소스 코드로 작성된다.
레시피는 건물 조사관이라고 생각하면 된다. 단지 실제 건물(소스 코드 리포지토리)을 돌아다니며 살피는 것이 아니라 세부적인 설계 도면(LST)을 사용해 다음과 같이 작업한다.
- - 모든 방(LST 노드)을 체계적으로 순회한다.
- - 각 방에서 주의를 기울일 부분이 있는지 확인한다(이 메서드 호출이 패턴과 일치하는가?).
- - 작업이 필요하다면 변경을 수행한다(LST 노드 수정).
- - 작업이 필요 없다면 다음으로 넘어간다.
- - 자동으로 다음 방으로 이동한다(LST 탐색).
다음 예시는 모든 의미 정보와 서식이 보존된 LST를 소스 코드와 비교한 것이다.
// Source code snippet // The user's name private String name = "Java"; // LST representation J.VariableDeclarations | "// The user's name\nprivate String name = "Java"" |---J.Modifier | "private" |---J.Identifier | "String" \---J.VariableDeclarations.NamedVariable | "name = "Java"" |---J.Identifier | "name" \---J.Literal | ""Java""레시피는 XML, YAML과 같은 다양한 파일 형식에서 메이븐(Maven) POM이나 기타 구성 파일을 수정할 수 있다. 또한 마이그레이션의 일부로 필요에 따라 새로운 파일을 생성하기도 한다. 그러나 레시피가 코드를 수정할 필요는 없다. LST의 풍부한 데이터가 제공하는 강력한 기능과 혜택은 데이터와 인사이트를 수집하고, 변경 전에 코드를 이해하는 데 도움이 되도록 코드베이스를 분석해 데이터 테이블을 생성한다는 점에 있다(이 데이터 테이블은 보고서, 메트릭 또는 시각화에 사용됨).
레시피 테스트 : 결정론적이고 신뢰할 수 있음
오픈리라이트가 가진 결정론적 특성은 손쉬운 레시피 테스트로 이어진다. 레시피가 수행해야 하는 변경 작업을 시각화하고 올바르게 작동하는지 검증하는 방법은 다음과 같이 간단하다.
@Test void migrateJUnitTest() { rewriteRun( // The recipe to test new MigrateToJUnit5(), // Before: JUnit 4 code java(""" import org.junit.Test; public class MyTest { @Test public void testSomething() {} } """), // After: Expected JUnit 5 result java(""" import org.junit.jupiter.api.Test; public class MyTest { @Test public void testSomething() {} } """) ); }이 테스트 프레임워크는 레시피가 더도, 덜도 아닌 딱 원하는 출력만 정확히 생성하는지 여부를 확인한다. 레시피는 결정론적이므로 동일한 입력은 항상 동일한 결과를 생성하고, 따라서 대규모 테스트가 가능하며 신뢰할 수 있다.
AI만 있으면 애플리케이션 현대화에 충분한가?
깃허브 코파일럿, 아마존 Q 디벨로퍼와 같은 AI 어시스턴트가 있는 만큼 ‘AI가 현대화를 알아서 처리할 수 있지 않나?’라는 질문이 자연스럽게 나올 수 있다.
AI는 강력하지만 다음과 같은 이유로 대규모 코드의 현대화에는 맞지 않는다.
- - 제한적인 컨텍스트. 모델은 전체 종속성 그래프 또는 조직 규칙을 볼 수 없다.
- - 확률론적인 출력. 오류율이 1%라 해도 대규모 환경에서는 수천 개의 빌드가 제대로 작동하지 않게 된다.
- - 반복 가능성의 부재. 각 AI 제안은 고유하므로 여러 리포지토리에 걸쳐 재사용할 수 없다.
- - 확장되지 않는 RAG. 검색 증강 생성은 수십억 라인의 코드를 일관적으로 처리할 수 없다. 컨텍스트가 많을수록 혼란도 커진다.
AI는 코드 요약, 개발자 의도 포착, 새 코드 작성, 결과 설명 등 보완적인 영역에서 탁월하다. 반면 오픈리라이트는 코드 파일별로, 리포지토리별로 일관적이고 정확한 변경을 수행하는 데 뛰어나다.
AI와 오픈리라이트 레시피는 툴 호출을 통해 함께 작동할 수 있다. AI가 질의를 해석하고 레시피를 조율하면 오픈리라이트는 컴파일러급 정확성으로 실제 변환을 수행한다. 또한 AI는 레시피 자체의 작성 속도를 높여주므로 개념에서 출발해 실제 작동하는 자동화에 이르기까지의 시간이 단축된다. 이렇게 AI를 적용하는 편이 AI가 직접 변경하는 방법보다 더 안전하다. 레시피는 결정론적이고 쉽게 테스트할 수 있고 리포지토리 간에 재사용이 가능하기 때문이다.
대규모 앱 현대화
개별 개발자는 빌드 툴로 메이븐에서는 mvn rewrite:run, 그래들에서는 gradle rewriteRun을 사용해 직접 오픈리라이트 레시피를 실행할 수 있다. 이 방법은 단일 리포지토리의 경우 효과적이지만 LST는 메모리 내에서 빌드되고 일시적이기 때문에 여러 리포지토리에 걸쳐 레시피를 실행해야 할 때는 적합하지 않다. 수백 또는 수천 개의 코드베이스로 확장한다면 리포지토리 단위로 이 프로세스를 반복해야 하므로 결국 규모가 커질수록 빠르게 효용성을 잃는다.
진정한 테스트는 대규모 엔터프라이즈 환경에서 수십억 라인의 코드가 포함된 수천 개의 리포지토리를 현대화하는 경우다. 오픈리라이트는 결정론적 자동화 엔진을 제공하지만 조직에는 엔진뿐만 아니라 애플리케이션 포트폴리오 전반에서 그 엔진을 운영하기 위한 방법도 필요하다. 바로 이 부분에 모던(Moderne)이 사용된다.
모던은 오픈리라이트를 수평 확장하는 플랫폼으로, 수천 개의 리포지토리에 걸쳐 레시피를 병렬로 실행하고 조직 계층 구조를 관리하고 CI/CD 파이프라인과 통합되고 수십억 라인의 코드에 대한 결과를 추적한다. 사실상 오픈리라이트를 강력한 프레임워크에서 대규모 현대화 시스템으로 바꿔주는 역할을 한다.
모던을 통해 다음을 실행할 수 있다.
- - 수백 개의 애플리케이션에 걸쳐 스프링부트 2.7에서 3.5로의 마이그레이션을 하나의 조율된 캠페인으로 실행
- - 비즈니스를 위한 핵심 리포지토리만이 아닌 모든 리포지토리에 보안 패치 적용
- - 로깅, 종속성 버전, 구성을 전사적으로 표준화
- - 대규모로 코드를 조사하고 이해. 변경을 수행하기 전에 수십억 라인의 코드를 몇 분 만에 쿼리해서 사용 패턴, 종속성 또는 위험을 파악
- - 대시보드와 보고서를 통해 변경이 미치는 영향을 확인함으로써 자동화에 대한 신뢰를 구축
이는 일련의 사일로화된 프로젝트가 아닌 지속적인 역량으로서의 현대화다. 전체 소프트웨어 환경을 하나의 클래스를 리팩터링하듯이 유동적으로 발전시키는 이 역량을 실무에서는 ‘기술 스택 유동성’이라고 지칭한다.
기술 부채를 해결하기 위한 레시피
프레임워크는 진화하고, API는 시간이 지나면 폐기되고, 보안 표준은 엄격해진다. 자동화를 구현하지 않으면 조직은 빠르게 기술 부채에 빠지게 된다.
오픈리라이트는 이 문제에 대처하기 위한 결정론적 기반을 제공한다. 무손실 시맨틱 트리는 완전한 충실도의 코드 표현을 제공하며 레시피는 변환을 정밀하고 반복 및 감사 가능한 작업으로 만들어준다. 모던 플랫폼과 결합하면 수십억 라인의 코드에 걸친 대규모 현대화가 가능하다.
AI는 앞으로도 계속 중요한 역할을 하면서 현대화를 대화 기반 작업으로 만들고 레시피 작성 속도를 높여줄 것이다. 그러나 결정론적 자동화는 확장 및 지속 가능한 안전한 현대화를 가능하게 해주는 기반이다. 오픈리라이트를 사용하면 코드베이스를 지속적으로, 안전하게, 대규모로 발전시켜 향후 수십 년의 미래까지 대비할 수 있다.
dl-itworldkorea@foundryco.com
Mark Heckler editor@itworld.co.kr
저작권자 Foundry & ITWorld, 무단 전재 및 재배포 금지
이 기사의 카테고리는 언론사의 분류를 따릅니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
