
AI 수능 점수, 해외 모델은 '80점대', 국내 모델은 '20점대'
국내 AI 업계 “모델 특성 반영 안해 나온 결과”…LG 자체 측정 결과 88점대까지
세계 10위권 AI 모델 개발 위해서는 측정 방식 다양하게 고려해 접근해야
 |
이미지ㅣ제미나이 생성 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
인더뉴스 이종현 기자ㅣ인공지능(AI)의 성능을 측정할 때 비전문가들도 이해할 수 있는 측정 지표 중 하나가 해당 AI가 푼 수능 점수입니다. 국내 유수의 전문가들이 심혈을 기울여 만든 시험인 만큼 해당 시험을 AI가 얼마나 잘 풀어내는지가 성능을 알 수 있는 하나의 지표가 된 것입니다.
지난 15일 김종락 서강대 수학과 교수 연구팀은 국내 기업의 AI 모델과 해외 AI 모델에게 수능 문제를 풀게 하고 그 결과를 비교하게 한 결과를 발표했습니다.
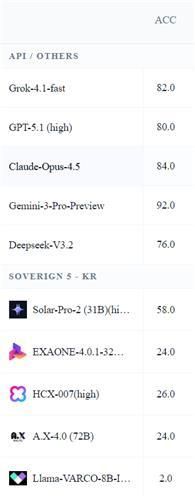
국내 AI 모델에는 업스테이지의 '솔라 프로-2', LG AI연구원의 '엑사원 4.0.1', 네이버의 'HCX-007' SK텔레콤[017670]의 'A.X 4.0(72B)' 엔씨소프트 경량모델 '라마 바르코 8B 인스트럭트' 등 과학기술정보통신부(과기정통부)의 독자 AI 파운데이션 모델 프로젝트에 참여 중인 5개 기업의 모델을 활용했으며 해외 모델에는 GPT-5.1, 제미니 3 프로 프리뷰, 클라우드 오푸스 4.5, 그록 4.1 패스트, 딥시크 V3.2 등 5개 모델을 사용했습니다.
수능 수학의 네 분야(공통과목, 확률과 통계, 미적분, 기하)에서 가장 난도가 높은 문제 5개씩 20문제, 국내 논술·인도 대학 입시 10문제씩, 일본 도쿄대 공과대학 대학원 입시 10문제 등 총 50개 문제를 풀게 한 결과, 해외 모델 5개는 모두 70점 이상의 점수를 기록했으며 그 중 '제미나이 3 프로'는 46문제를 맞히며 92점이라는 점수를 보였습니다.
반면, 국내 모델들은 58점을 기록한 '솔라 프로2'를 제외하고는 모두 20점대의 정답률을 보이며 해외 모델들에 비해 떨어지는 결과를 보였다고 연구팀은 밝혔습니다.
 |
수능 20문제+논술 30문제 풀이 결과. 사진ㅣ김종락 서강대 교수팀 제공 |
연구팀은 "국내 5개 모델의 경우 단순 추론으로는 문제를 대부분 풀지 못해 파이선을 툴로 사용하도록 설계해 문제 적중률을 높였음에도 이런 결과가 나왔다"라고 설명했습니다.
이에 대해 국내 AI 업계는 국내 AI 개발사들이 산업용 AI 개발에 집중했기에 수능 풀이와 같은 측정 방식으로는 점수가 낮게 나올 수 있다고 지적했습니다. 또한, 단계별로 검증을 거치는 추론 방식인 해외 모델들과 달리 사전학습 방식 AI는 수학·코딩 등 논리적 문제풀이에 상대적으로 약한 것도 결과에 영향을 미쳤다고도 설명했습니다.
LG AI연구원도 이러한 연구팀의 연구 결과에 정면 반박했습니다. LG AI연구원 측은 동일한 문제로 내부 재측정을 한 결과 자사 AI 모델 엑사원(EXAONE)의 수학 점수는 88.75점까지 기록했다고 밝혔습니다.
LG AI연구원은 "서강대 평가 방식이 모델 특성을 반영하지 않아 점수가 낮게 나왔다"라고 반박하며 "파이썬 도구 사용이 성능 측정에 포함됐다는 설명에 문제가 있다"라고 설명했습니다.
LG AI 연구원 측의 측정은 논술 문제를 제외한 수능 수학 20문제 만으로 진행됐으며 측정을 반복한 결과 평균 88.75점의 점수를 기록한 것으로 전해졌습니다.
이에 대해 AI 업계 관계자들은 평가 방식과 모델 세부 설정에 따라 측정 결과가 달라질 수 있으며 수능 시험 결과가 AI 모델 성능을 측정할 수 있는 절대적 지표는 아님을 지적했습니다.
그러면서도 결국 한국이 세계 10위권 안에 드는 독자 AI 파운데이션 모델을 개발하는 것을 목표로 하고 있는 한, 다양한 측정 방식을 종합적으로 고려한 전략적 접근이 필요하다고도 강조했습니다. 한 관계자는 "서강대 연구팀의 연구처럼 종합적인 문제 풀이 능력을 측정하는 방식과 모델의 특성을 반영한 테스트 모두 중요한 사안"이라고 설명하기도 했습니다.
배경훈 부총리 겸 과학기술정보통신부 장관은 15일 세종시에서 가진 기자 간담회에서 "독자 AI 파운데이션 모델을 개발하는 기업들은 그동안 사업적 목적에 맞게 AI 모델을 만들어왔고 과학과 수학 등에 특화된 추론형 AI 모델을 개발을 위한 데이터 학습이 부족했던 게 사실"이라며 "예를 들어 화학 분야의 분자 구조식을 AI가 인식할 수 있는 형태로 데이터를 변환하는 등 각 분야별 특화 데이터를 만들어 학습시킨다면 글로벌 톱10에 해당하는 경쟁력을 가질 수 있다"라고 말했습니다.
 |
15일 오전 세종시 정부세종청사 인근 식당에서 열린 과학기술정보통신부 기자간담회에서 기자들과 질의응답을 하고 있는 배경훈 과학기술정보통신부 장관. 사진ㅣ과학기술정보통신부 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
한편, 독자 AI 파운데이션 모델 프로젝트에 참여 중인 네이버클라우드는 프로젝트 참여용 모델인 '하이퍼클로바X 추론 32B 모델'이 올해 수능 문제를 푼 결과 주요 과목에서 모두 1등급을 받았다고 26일 밝혔습니다.
수능 주요 영역인 국어, 수학, 영어 전 문항을 대상으로 진행된 테스트에서 해당 모델은 국어 영역 선택 과목인 '언어와 매체'와 '화법과 작문' 모두 89점을 기록하며 1등급을, 수학 영역에서는 '기하' 92점, '확률과 통계' 92점, '미적분' 89점으로 선택과목 전반에서 1등급 수준의 점수를 달성했습니다.
특히, 영어 영역은 100점을 달성하며 모델의 추론 능력을 입증했다고 강조했습니다.
네이버클라우드 관계자는 "32B의 비교적 작은 모델로도 수능 주요 과목에서 1등급을 획득하며 작은 모델의 가능성을 입증했다"라며 "곧 선보일 독자 AI 파운데이션의 옴니모달 모델과 함께 산업과 일상 전반에서 활용할 수 있는 고성능·고효율 AI 기술 경쟁력을 꾸준히 강화할 것"이라고 말했습니다.
Copyright @2013~2025 iN THE NEWS Corp. All rights reserved.
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
