
 |
엔비디아는 2025년 12월 초 CUDA 13.1을 선보였다 / NVIDIA |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
하드웨어에 영혼을 불어넣다
원래 GPU는 게임 그래픽이나 그리던 장치였어요.
복잡한 수학 계산이나 AI 학습에 쓰기에는 활용하기 까다로운 장치였죠. 그런데 2006년, 엔비디아는 CUDA(Compute Unified Device Architecture)라는 소프트웨어 플랫폼을 세상에 내놓습니다.
쉽게 말해, 프로그래머들이 어려운 기계어 대신 익숙한 언어로 GPU에게 “자, 이제 AI 연산을 시작해!”라고 명령을 내릴 수 있는 통로를 열어준 거예요. 잠자고 있던 GPU의 병렬 연산 능력을 깨워 AI라는 거대한 파도를 타게 만든 결정적인 순간이었죠.
왜 모두가 CUDA에 열광할까?
사실 경쟁사들도 비슷한 성능의 칩을 만들 수는 있어요.
하지만 전 세계 AI 개발자들은 여전히 엔비디아를 떠나지 못하죠. 왜 그럴까요?
바로 20년 가까이 쌓아온 압도적인 생태계 때문이에요.
CUDA 안에는 AI 학습 속도를 획기적으로 끌어올리는 cuDNN이나 복잡한 수학 문제를 순식간에 푸는 라이브러리들이 빽빽하게 들어차 있어요. 개발자 입장에선 이미 모든 도구가 완벽하게 갖춰진 고급 주방(CUDA)을 두고, 도구도 부족한 새 주방으로 옮길 이유가 전혀 없죠. 이 강력한 소프트웨어의 결속력이 엔비디아를 무너뜨릴 수 없는 요새로 만들었습니다.
 |
왼쪽의 Block-level 모델은 작업을 타일 단위로 나누는 CUDA Tile 방식으로, 개발자가 블록 수준의 병렬성에 집중할 수 있도록 설계됐다. 반면 오른쪽의 Thread-level 모델은 기존 CUDA SIMT 방식으로, 스레드 단위의 세밀한 병렬 제어가 필요하다. CUDA 타일은 하드웨어 제어 부담을 줄이고, 블록 단위 알고리즘에 집중할 수 있게 한 CUDA의 새로운 병렬 프로그래밍 방식이다. / NVIDIA |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
하드웨어를 넘어 '지능형 플랫폼'으로
이제 CUDA는 단순히 연산을 돕는 도구에 머물지 않아요.
엔비디아는 NVIDIA NIM(NVIDIA Inference Microservices) 같은 마이크로서비스를 통해 누구나 클릭 몇 번으로 최신 AI 모델을 CUDA 위에서 즉시 배포할 수 있게 만들었어요.
GPU가 튼튼한 육체라면, CUDA는 그 육체가 가진 힘을 100%, 아니 200% 활용하게 만드는 지능형 신경계와 같아요. 엔비디아가 소프트웨어 기술에 쏟아부은 이 심원한 투자가 결국 오늘날 전 세계 AI 개발자들이 사용하는 '공용어'를 만들어낸 것이죠.
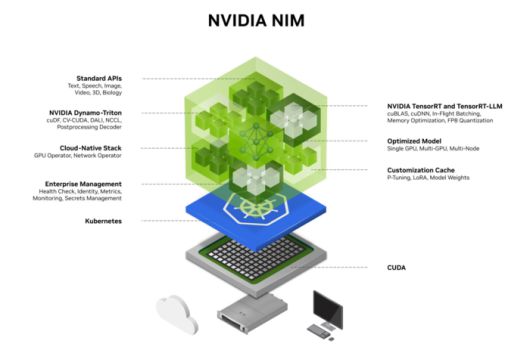 |
NIM 구조 / NVIDIA |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
소프트웨어가 길을 닦고, 하드웨어가 달린다
보통은 기계를 먼저 만들고 그에 맞는 프로그램을 짜기 마련이지만, 엔비디아는 정반대의 길을 걸어왔어요.
소프트웨어가 어떤 계산을 가장 힘들어하는지 먼저 파악하고, 그 계산을 가장 시원하게 해결해 줄 수 있는 구조로 하드웨어를 설계했죠. 이를 '하드웨어-소프트웨어 공동 설계'라고 불러요.
현재 엔비디아의 최신 칩들이 다른 회사 제품보다 압도적으로 효율적인 이유는, 칩이 태어나기도 전부터 CUDA라는 완벽한 조종사가 그 길을 미리 닦아놓았기 때문입니다. 이 두 바퀴가 완벽하게 맞물려 돌아가기에 엔비디아의 질주는 멈추지 않는 것이죠.
「수만 개의 칩을 하나로 잇는 신경망, 초고속 네트워킹」 편에서 이어집니다.
최성훈 기자 csh87@etnews.com
[Copyright © 전자신문. 무단전재-재배포금지]
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
