
 |
대형 멀티모달 모델은 문서 이해 분야에서 높은 성능을 보여주고 있지만, 높은 연산 비용과 긴 지연 시간 때문에 실제 서비스 환경이나 엣지 기기에서 활용하기에는 한계가 있다. 이러한 문제를 해결하기 위해 성능과 효율의 균형을 동시에 겨냥한 경량 문서 인식(OCR) 모델이 등장했다.
지푸 AI와 칭화대학교 연구진은 15일(현지시간) 경량 멀티모달 문서 이해 모델 'GLM-OCR'을 온라인 아카이브를 통해 공개했다.
연구진은 이 모델이 낮은 연산 비용과 빠른 처리 속도를 유지하면서도 복잡한 문서 구조를 이해할 수 있도록 설계됐다고 설명했다.
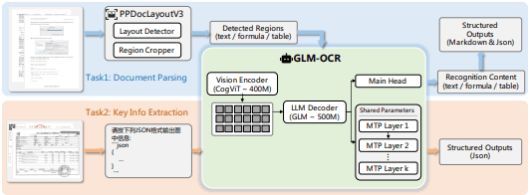
GLM-OCR은 9억(0.9B) 매개변수 규모다. 0.4B 매개변수 규모의 시각 인코더 CogViT, 경량 크로스모달 연결 모듈, 0.5B 매개변수의 GLM 언어 디코더로 구성돼 있다.
핵심 기술 중 하나는 멀티 토큰 예측(MTP)이다.
일반적인 LLM 기반 OCR 시스템은 한 번에 하나의 토큰만 예측하는 자동회귀(autoregressive) 방식을 사용한다. 하지만 OCR 작업은 구조가 비교적 결정적인 경우가 많아 이 방식이 비효율적일 수 있다.
GLM-OCR은 한 단계에서 여러 토큰을 동시에 예측하도록 설계됐다. 학습 단계에서는 한번에 10개의 토큰을 동시에 예측하도록 훈련하며, 실제 추론 과정에서는 평균적으로 약 5.2개의 토큰을 생성한다.
이 방식으로 약 50%의 처리 속도 향상을 달성했다. 또 매개변수 공유 구조를 사용해 메모리 사용량 증가도 최소화했다.
GLM-OCR은 일반적인 비전-언어 모델(VLM)처럼 문서를 단순히 좌측에서 우측으로 읽는 방식을 사용하지 않는다. 대신 GLM-OCR은 2단계 처리 파이프라인을 사용한다.
먼저 레이아웃 분석 단계에서 PP-DocLayout-V3 모델이 문서 내에서 의미 있는 영역을 탐지한다. 이후 영역별 병렬 인식 단계에서 각 영역을 병렬로 처리해 텍스트와 구조를 인식한다.
이러한 방식은 특히 표나 수식, 여러 열이 혼합된 문서에서 처리 효율과 인식 정확도를 높이는 데 도움이 된다.
GLM-OCR은 단순한 텍스트 인식에 그치지 않고 다양한 문서 처리 작업을 수행할 수 있다. 대표적으로 문서 파싱과 구조화, 텍스트 및 수식 전사, 표 구조 복원, 핵심 정보 추출(KIE) 등의 기능을 지원한다.
문서 파싱 작업에서는 마크다운이나 JSON 형태의 구조화된 결과를 생성하며, KIE 작업에서는 문서 이미지를 입력하면 필요한 정보를 추출해 JSON 형식으로 직접 출력한다.
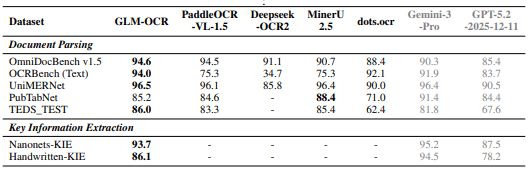 |
연구진은 공개 벤치마크에서 GLM-OCR이 높은 성능을 보였다고 밝혔다.
'옴니독벤치(OmniDocBench) v1.5'에서 94.6점, 'OCR벤치(텍스트)'에서 94.0점, 'UniMERNet'에서 96.5점, 'PubTabNet'에서 85.2점, 'TEDS_TEST'에서 86.0점을 기록했다. 핵심 정보 추출(KIE) 분야에서도 'Nanonets-KIE' 93.7점, 'Handwritten-KIE' 86.1점 등 높은 성능을 보였다.
다만 표 인식 벤치마크인 PubTabNet에서는 88.4점을 기록한 'MinerU 2.5' 모델에 뒤졌다. 연구진도 이 모델이 모든 분야에서 최고 성능을 기록한다고 주장하지는 않았다.
GLM-OCR은 실제 서비스 환경에서의 활용을 고려해 개발됐다. 연구진에 따르면 이 모델은 vLLM, SGLang, 올마(Ollama) 등의 프레임워크와 호환되며, 라마-팩토리(LLaMA-Factory)를 통해 미세조정도 가능하다.
평가 환경 기준 처리 속도는 초당 약 0.67장의 이미지와 초당 1.86페이지의 PDF 문서를 처리하는 수준으로 보고됐다. 또한 모델 서비스(MaaS) API도 제공되며, 사용 비용은 100만 토큰당 0.2위안으로 책정됐다.
GLM-OCR은 허깅페이스와 깃허브를 통해 사용 가능하다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
