
실존 도시를 기반으로 한 AI 시뮬레이션이 현실화되고 있다. 가상의 장면을 만들어내던 기존 생성 모델과 달리, 실제 도시를 그대로 재현하고 자유롭게 탐색할 수 있는 새로운 형태의 '월드 모델'이 등장했다.
네이버와 한국과학기술원(KAIST), 서울대학교 연구진은 16일 서울을 기반으로 한 도시 규모의 생성 모델 '서울 월드 모델(SWM·Seoul World Mode)'을 온라인 아카이브를 통해 공개했다.
이 모델은 단순히 그럴듯한 장면을 만들어내는 것이 아니라, 실제 존재하는 도시의 거리와 건물 배치를 반영해 영상을 생성하는 것이 핵심 특징이다.
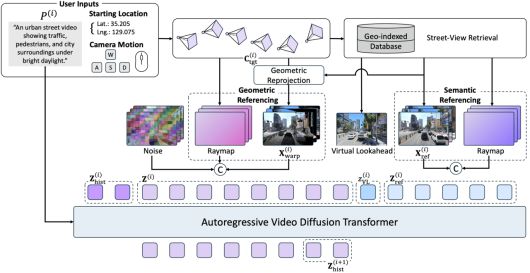
기존 영상 생성 모델들은 보이지 않는 영역까지 모두 상상해 만들어내는 방식이었다. 하지만, SWM은 실제 서울의 거리 데이터를 기반으로 작동한다. 특정 좌표와 카메라 움직임, 텍스트 명령을 입력하면, 해당 위치 주변의 스트리트뷰 이미지를 불러와 이를 기반으로 영상을 생성한다.
이 과정에서 모델은 단순히 이미지를 이어붙이는 것이 아니라, 공간 구조와 시각적 특징을 동시에 반영해 새로운 영상을 만들어낸다. 이를 통해 실제 도시와 일치하는 공간적 정확성과 시간적 일관성을 확보했다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
기존 모델은 시간이 길어질수록 품질이 급격히 떨어지는 문제가 있었지만, SWM은 '가상 예측 싱크(Virtual Lookahead Sink)'라는 구조를 통해 이를 해결했다. 이 방식은 미래 위치의 이미지를 지속적으로 참조해 영상 생성 과정에서 기준점을 유지하도록 하는 기술로, 장거리에서도 공간 일관성을 확보한다.
또 다른 강점은 다양한 카메라 이동을 지원한다는 점이다. 단순히 자동차 주행 시점에 국한되지 않고, 보행자 시점, 교차로 이동, 자유로운 카메라 경로 등 다양한 시나리오를 구현할 수 있다.
이는 실제 데이터의 한계를 보완하기 위해 합성 데이터를 활용한 결과다. 연구진은 CARLA 기반 시뮬레이터를 통해 보행, 차량, 자유 이동 등 다양한 경로 데이터를 생성해 모델의 일반화 성능을 높였다.
SWM은 텍스트 입력을 통해 도시 장면을 변형하는 것도 가능하다. 예를 들어, 도심에 거대한 파도를 만들거나, 빌딩 사이에 괴수를 등장시키는 등 현실과 상상을 결합한 시나리오를 생성할 수 있다.
이는 실제 도시 구조를 유지하면서도 다양한 상황을 시뮬레이션할 수 있는 '현실 기반 생성 AI'의 가능성을 보여준다.
모델은 서울 전역에서 수집된 약 120만장의 파노라마 이미지와 1만개 이상의 합성 영상 데이터를 학습했다. 특히 서로 다른 시간에 촬영된 데이터를 활용하는 '크로스 템포럴 페어링(Cross Temporal Pairing)' 기법을 통해, 차량이나 사람 같은 일시적 요소가 아닌 도시의 고정된 구조를 학습하도록 설계됐다.
또 드문 간격으로 존재하는 거리 이미지를 자연스럽게 연결하기 위해 '뷰 보간(view interpolation)' 기술을 적용해 연속적인 영상 생성이 가능하도록 했다.
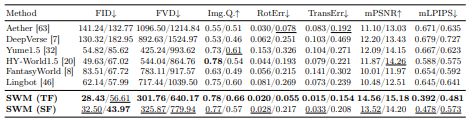 |
연구진은 서울뿐 아니라 부산과 미국 미시간주 앤 아버에서도 성능을 비교 평가했다. 그 결과, SWM은 공간적 정확성과 시간적 일관성, 장거리 생성 능력에서 기존 영상 생성 모델을 앞서는 것으로 나타났다.
SWM은 단순한 영상 생성 기술을 넘어, AI 에이전트와 디지털 트윈 구현의 핵심 기술로 평가된다. 실제 도시를 기반으로 한 고정밀 시뮬레이션이 가능해지면서, 자율주행, 로보틱스, 도시 계획, 게임 등 다양한 분야로 확장될 수 있기 때문이다.
특히 실제 환경을 기반으로 한 장거리 시뮬레이션과 자유로운 탐색 기능은, 앞으로 '현실 기반 AI 에이전트' 개발에 중요한 역할을 할 것으로 전망된다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
