
자연스러운 발화와 빠른 응답 속도, 높은 신뢰성을 동시에 구현하려는 경쟁이 치열해지는 음성 AI 분야에서 텍스트와 음성을 동일한 속도로 처리하는 새로운 음성 생성 기술이 공개됐다.
음성 AI 전문 흄 AI는 10일(현지시간) 새로운 음성 합성 기술 'TADA(Text-Acoustic Dual Alignment)'를 발표하고, 모델과 코드를 허깅페이스와 깃허브에 오픈소스로 공개했다.
이 기술은 텍스트와 음성을 1대 1로 정렬하는 토큰 구조를 도입, 기존 대형언어모델(LLM)의 음성 합성(TTS) 한계를 해결하는 것을 목표로 한다.
현재 음성 합성 시스템은 대부분 LLM을 기반으로 작동한다. 하지만 텍스트와 음성 데이터의 정보 밀도 차이 때문에 기술적인 문제가 발생한다.
일반적으로 1초 분량의 음성에는 약 12.5~25개의 음향 프레임이 포함되지만, 같은 길이의 텍스트는 보통 2~3개의 토큰에 불과하다. 이 때문에 모델 내부에서는 텍스트 토큰보다 훨씬 많은 오디오 토큰을 처리하는 구조적 불균형이 발생한다.
이러한 구조는 여러 문제를 낳는다. 먼저 더 긴 컨텍스트 윈도우가 필요해지고, 그에 따라 메모리 사용량이 크게 증가한다. 또 추론 속도가 느려질 수 있으며, 음성 생성 과정에서 단어가 누락되거나 환각이 발생하는 문제도 나타날 수 있다.
기존 시스템들은 이를 해결하기 위해 오디오 프레임 수를 줄이거나 텍스트와 음성 사이에 중간 단계의 의미 토큰(semantic tokens)을 추가하는 방식을 사용해 왔다. 그러나 이러한 방법은 음성 표현력이 떨어지거나 시스템 구조가 복잡해지는 단점을 갖는다.
TADA는 기존 접근과 달리 텍스트와 음성을 동일한 속도로 처리하는 구조를 도입했다.
이 기술의 핵심은 텍스트와 음성을 1대 1로 대응시키는 구조다. 먼저 텍스트 토큰 하나마다 하나의 음향 벡터를 생성하고, 이를 통해 텍스트와 음성이 완전히 동기화된 단일 스트림 형태로 LLM을 통과하도록 설계했다. 이후 LLM의 출력 상태를 기반으로 음향 특징을 생성하고 이를 실제 오디오로 변환한다.
이 구조에서는 LLM의 한 단계가 텍스트 토큰 하나와 오디오 프레임 하나를 동시에 생성하게 된다.
이 때문에 모델이 내용을 건너뛰거나 새로운 단어를 만들어내는 문제가 발생하기 어렵다는 것이 연구진의 설명이다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
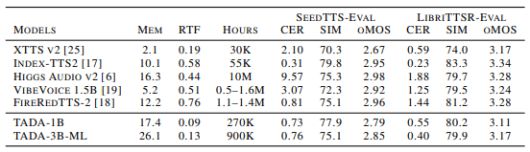
TADA의 가장 큰 특징은 속도와 효율성이다. 실시간 계수(Real-Time Factor)는 0.09로, 비슷한 수준의 LLM 기반 TTS 시스템보다 5배 이상 빠른 성능을 보였다.
이러한 속도 향상의 이유는 토큰 처리량에 있다. 기존 방식에서는 초당 약 12.5~75개의 오디오 토큰을 처리해야 했지만, TADA 방식에서는 초당 2~3개의 토큰만 처리하면 된다. 처리할 토큰 수가 크게 줄어들면서 전체 연산량과 지연 시간이 동시에 감소한다.
테스트 데이터셋 'LibriTTSR'에서 1000개 이상의 샘플을 평가한 결과, 음성 내용 환각이 단 한건도 발생하지 않았다고 연구진은 밝혔다.
또 다른 특징은 경량화된 구조다. 모델이 비교적 적은 연산량으로 작동하도록 설계돼 스마트폰이나 엣지 디바이스에서도 실행할 수 있다.
클라우드 서버를 호출하지 않고도 기기 자체에서 음성 생성이 가능해지며, 지연 시간도 낮아진다. 또 음성 데이터가 외부 서버로 전송되지 않기 때문에 사용자 데이터 프라이버시도 강화된다.
TADA의 동기화 구조는 컨텍스트 효율성에서도 강점을 보인다. 일반적인 TTS 시스템은 2048 토큰 컨텍스트 기준 약 70초 분량의 음성을 처리할 수 있지만, TADA는 같은 조건에서 약 700초(약 11분)의 음성을 처리할 수 있다.
이는 장시간 내레이션이나 장문 콘텐츠 낭독, 다중 턴 음성 대화와 같은 응용 분야에서 중요한 장점으로 작용한다.
이러한 이유로 음성 인터페이스를 개발하는 기업에 TADA는 온디바이스 AI 음성 기술로 활용될 가능성이 높다는 평가가 나온다.
하지만, 연구진은 기술적 과제가 남아 있다고 밝혔다. 예를 들어, 긴 음성을 생성할 때 화자의 목소리가 조금씩 변하는 '스피커 드리프트(speaker drift)' 현상이 가끔 발생한다. 또 음성과 텍스트를 동시에 생성할 경우 텍스트 품질이 낮아지는 문제도 발견됐다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
