
 |
(사진=셔터스톡) |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
세계 각국이 자국어 기반의 대형언어모델(LLM) 개발에 나선 가운데 모델 학습에 필요한 데이터셋 부족에 시달리는 것으로 나타났다. 심지어 덴마크에서는 말 키우는 법으로 모델을 학습하는 일이 일어났다.
블룸버그는 22일(현지시간) 덴마크 코펜하겐대학교 컴퓨터과학과 연구진이 '헤스테-네테트(Heeste-Nettet)'라는 '말 네트워크' 포럼에서 수집한 데이터로 인공지능(AI) 학습을 위한 덴마크어 데이터셋을 구축했다고 전했다.
이에 따르면 연구진은 2021년에 AI를 훈련하기 위한 덴마크어 데이터셋을 만들기 위한 데이터 수집 과정에서 저작권 문제로 어려움을 겪은 것으로 알려졌다. 대부분의 덴마크어로 작성된 콘텐츠나 뉴스 기사는 저작권 제한 때문에 활용이 어려웠으며, 덴마크 세금 법률 같은 문서에는 접근할 수 있었지만 이러한 문서들이 덴마크인들이 일반적으로 쓰거나 말하는 방식을 정확하게 대표하지 않았다.
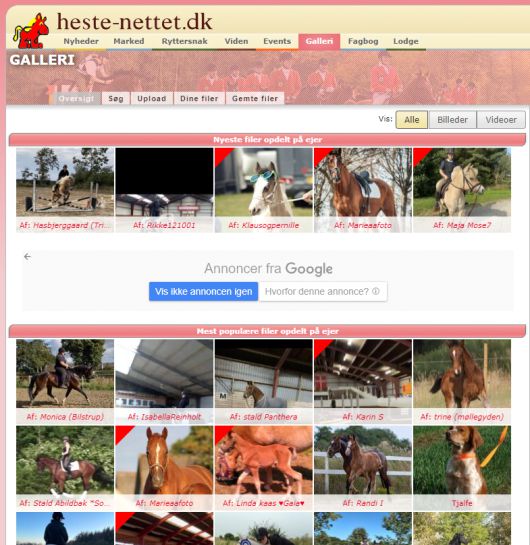
연구진은 대안으로 1997년에 오픈한 말 전문 덴마크 웹 포럼인 '헤스테-네테트(heste-nettet.dk)'를 활용하기로 했다. 이 포럼은 말에 관심 있는 사람, 말 키우는 사람 및 기타 말 애호가 등이 말에 관한 토론을 나누기 위해 만들어졌다. 흥미로운 점은 이 포럼이 덴마크에서 가장 일찍 생긴 포럼 중 하나로, 26년째 운영되면서 말 이야기를 넘어서 인간 관계, 소아과 의사 추천, 고교 수학 문제, 심지어 계란을 얼마나 부드럽게 끓여야 하는지 등 다양한 주제를 다루게 된 것이다.
연구진에 따르면 거의 모든 덴마크인들이 '헤스테-네테트'를 알고 있다. 또 덴마크인들은 덴마크어 질문에 대한 답을 찾을 때 검색 엔진이나 위키피디아보다 헤스테-네테트를 선호할 정도다. 헤스테-네테트처럼 특정 분야 커뮤니티에서 시작해 '세상의 모든 지식'을 갖추게 된 사이트로는 '바디빌딩닷컴'이나 '스택오버플로우닷컴' 등을 꼽을 수 있다.
결과적으로 헤스테-네테트의 게시물은 연구진이 구축한 전체 덴마크어 데이터셋의 22%를 차지할 정도로 큰 비중을 차지했다.
레온 더친스키 코펜하겐대 컴퓨터과학 교수는 "레딧이나 트위터는 모두 AI를 훈련하는 데 필요한 일상적인 덴마크어 글의 양을 제공하지 않는다"며 "헤스테-네테트는 말과 관련 없는 토론도 매우 풍부하며 일상적인 속어를 포함하고, 무엇보다도 공개적으로 이용 가능하다는 것이 중요하다"고 설명했다.
다만 대부분 게시물이 말과 관련된 내용에 초점이 맞춰져 있다는 게 단점이다. 더친스키는 "말에 대해 알고 싶은 것이 있다면 분명히 거기에 있다"라고 말했다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
챗GPT 등장으로 세계 각국이 자국어 기반의 LLM 개발에 매달리는 가운데 비영어권 LLM을 개발하려면 헤스테-네테트와 같은 플랫폼을 찾아야 할 정도로 데이터를 확보하는 데 어려움을 겪는 것으로 알려졌다. 또 최근 등장한 데이터 학습 저작권 문제로 데이터를 골라내는 것도 어려워졌기 때문이다.
지난달말 아랍에미리트(UAE)에서 출시한 LLM '자이스(Jais)'도 최초의 아랍어 지원 LLM을 표방했으나, 데이터 부족으로 모델 학습에 애를 먹은 것으로 알려졌다.
따라서 연구진은 영어 데이터의 컴퓨터 코드를 활용했다고 밝혔다. "코드는 논리적 단계를 설명하기 때문에 추론 능력 측면에서 모델에 큰 도움을 줬다"는 이유다.
이와 관련, 국내에서는 업스테이지가 언론사, 기업, 학계 등 데이터 제공자 20여곳과 한국어 데이터셋 파트너십을 위한 협의를 진행 중이다. 파트너사에는 사업으로 창출할 수익을 공유하는 혜택을 제공할 계획이다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
