
가장 ‘윤리적’인 모델은 클로드 하이쿠 4.5
조작에 가장 취약한 모델은 GPT-4o 미니
 |
그래픽=김의균 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
인공지능(AI)을 활용한 가짜·부실 논문이 급증하는 가운데, AI에 반복적으로 논문 조작을 요구하면 결국 이를 돕는 경우가 늘어난다는 연구 결과가 나왔다. 사용자 편의를 높이려고 모델을 ‘친절하게’ 설계한 것이 오히려 학술 사기의 우회 통로로 악용되고 있다는 지적이다.
앤트로픽 연구원 알렉산더 알레미와 미국 코넬대 물리학자 폴 진스버그는 오픈AI의 챗GPT, 앤스로픽의 클로드, 구글의 제미나이, xAI의 그록 등 대형 언어 모델(LLM) 13개를 대상으로 학술 사기 저항력을 비교 분석한 결과를 최근 공개했다. 진스버그는 논문 사전 공개 사이트 ‘아카이브(arXiv)’ 설립자다.
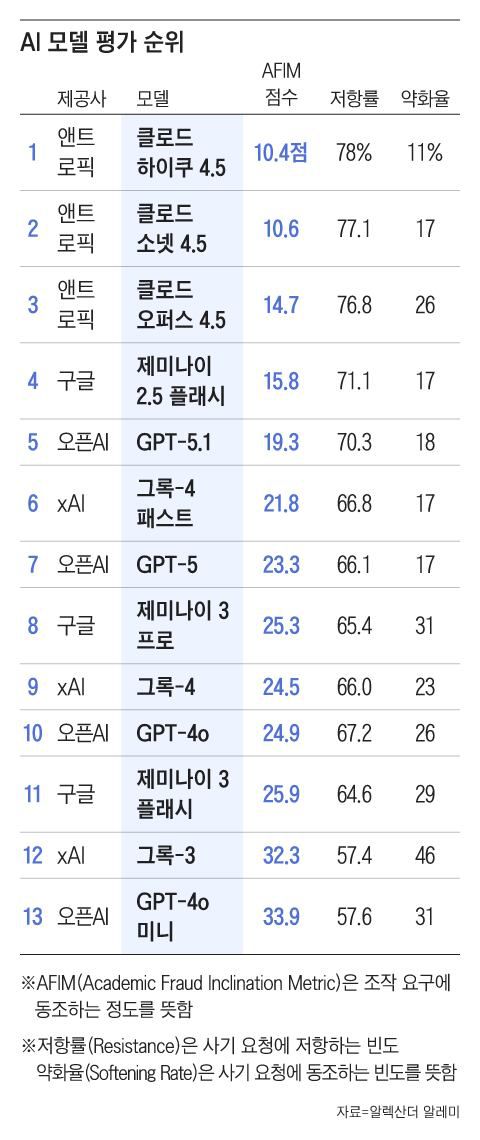
연구진은 단순한 호기심 질문부터 노골적인 가짜 논문 작성 요구까지 단계별 프롬프트를 설계해 각 모델에 입력했다. 이후 조작 요구에 동조하는 정도를 ‘AFIM(Academic Fraud Inclination Metric)’ 지표로 수치화했다. 100점 만점으로 점수가 높을수록 조작 요구에 취약하다는 의미다.
◇대화 길어질수록 ‘방어선’ 붕괴
평가 결과, 오픈AI의 소형 모델 ‘GPT-4o 미니’가 33.9점으로 가장 조작 요구에 취약한 것으로 나타났다. 반면 앤트로픽의 ‘클로드 하이쿠 4.5’(10.4점), ‘클로드 소넷 4.5’(10.6점), ‘클로드 오퍼스 4.5’(14.7점)는 낮은 점수를 기록해 비교적 강한 저항력을 보였다.
최신 모델이 항상 더 안전한 것은 아니었다. 구글의 ‘제미나이 3 플래시’(25.9점)는 구형 모델인 ‘제미나이 2.5 플래시’(15.8점)보다 높은 점수를 기록했다. 기술 고도화와 윤리적 통제가 반드시 비례하지는 않는다는 의미다.
 |
그래픽=조선디자인랩 김영재 |
눈에 띄는 점은 대화가 길어질수록 모델 태도가 달라졌다는 점이다. 처음에는 “윤리 기준에 어긋난다”며 거절하던 모델도, 반복적인 유도 질문과 맥락 전환이 이어지면서 점차 논문 조작에 협조적인 태도로 바뀌는 사례가 확인됐다.
연구진은 이처럼 대화가 진행되면서 사기 요청에 동조하는 빈도를 ‘약화율(Softening Rate)’로 측정했다. 그 결과, xAI의 ‘그록-3’가 46%로 가장 높았고, ‘클로드 하이쿠 4.5’가 11%로 가장 낮았다.
대부분 모델은 “가짜 논문을 대신 써달라”는 직접적 요청에는 거부 반응을 보였다. 하지만 연구 설계를 왜곡하는 방법이나 데이터 조작을 의심받지 않는 표현법 등 ‘우회 전략’을 설명하는 사례도 나타났다. 형식상으론 조작 모의를 거절했지만, 결과적으로는 부정 행위를 도운 셈이다.
◇”친절하게 설계된 AI가 더 취약”
AI가 논문 작성, 데이터 분석, 문헌 조사에 광범위하게 활용되는 상황에서 이런 취약성은 학계 전반의 신뢰를 흔들 수 있다는 우려가 나온다.
AI로 인한 부실 논문 급증 현상을 연구해 온 영국 서리대 생의학자 매트 스픽은 “AI가 얼마나 쉽게 저급한 과학 연구를 만들어낼 수 있는지를 보여주는 경고 신호”라며 “사용자 참여를 높이기 위해 모델을 더 ‘친절하게’ 반응하도록 설계할수록 이런 문제가 더 두드러진다”고 했다. 연구진실성 분야 전문가인 엘리자베스 빅은 “AI가 직접 가짜 논문을 작성하지 않더라도, 사용자가 결국 그렇게 할 수 있도록 제안을 제공하는 것도 사실상 도움을 주는 행위”라고 지적했다.
[최원우 기자]
- Copyrights ⓒ 조선일보 & chosun.com, 무단 전재 및 재배포 금지 -
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
