
 |
가상의 인공지능(AI) 학습모델이 방대한 합성데이터를 적극 활용해 자율자동차 사고 위험 분석에 집중하고 있는 모습을 생성형 인공지능을 활용해 그렸다. 챗GPT |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
오픈AI가 차세대 대형언어모델(LLM) GPT-5 개발을 앞두고 데이터 확보에 비상이 걸렸다. 인공지능(AI) 모델의 성능을 높이기 위해서는 방대한 양의 고품질 데이터가 필요하다. 문제는 LLM 규모가 워낙 빠르게 커지다 보니 AI 학습에 필요한 양질의 데이터가 고갈되고 있는 것이다.
정보기술(IT) 업계에선 향후 2년 내 고품질 텍스트 데이터에 대한 수요가 공급을 넘어설 것으로 예상한다. 이 같은 데이터 초과 수요 탓에 지금껏 폭발적으로 발전했던 AI 성장세가 꺾일 수 있다는 우려도 나온다.
최근 월스트리트저널(WSJ)은 "오픈AI가 개발 중인 'GPT-5'의 경우 지금의 성장 추세를 따른다면 60조~100조개의 데이터 토큰(문장 최소 단위)이 필요하다"며 "이는 현재 활용 가능한 모든 고품질 텍스트 데이터를 10조~20조개 넘어서는 수준"이라고 설명했다. 지난해 출시된 GPT-4가 최대 12조개의 데이터 토큰을 학습한 것으로 알려졌는데 GPT-5의 경우 이보다 8배가 많은 데이터가 필요하다는 계산이다.
이 같은 데이터 부족 문제를 해결하기 위한 방안으로 '합성데이터(Synthetic data)'가 부상하고 있다. 합성데이터는 실제 데이터를 모방해 인공적으로 만든 가상 데이터다. 유럽데이터보호감독기구(EDPS)는 합성데이터를 '원래 데이터 소스를 가져와 유사한 통계 속성을 가진 새로운 인공 데이터를 생성하는 것'으로 정의한다.
합성데이터의 장점은 실제 데이터의 단점에서 엿볼 수 있다. 인간이 만들어내는 실제 데이터는 AI 학습용으로 이용하기엔 현실적인 제약이 있다.
김민진 정보통신정책연구원(KISDI) 연구원은 "실제 데이터는 개인정보 보호 이슈에 직면하기 때문에 온전히 활용하기엔 한계가 있다"며 "아울러 AI 성능을 높이기 위해 '데이터 정제'를 하는 과정에서 시간과 비용이 많이 들어가는 데다 정확성·일관성·적시성 측면에서 고품질 데이터 수집이 쉽지 않다"고 설명했다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
반면 합성데이터는 이런 제약 조건에서 상대적으로 자유롭다. 가상 데이터이기 때문에 개인정보 노출 위험이 낮다. 또 다양한 상황을 가정해 수많은 데이터를 생성할 수 있어 데이터 부족으로 인한 AI 모델의 성능 저하 문제도 극복할 수 있다. 컴퓨터 알고리즘이 실제 데이터의 특징을 반영해 무한대로 생성한다. 텍스트, 이미지, 비디오, 음성 등 다양한 형태의 데이터로 만들 수 있다. 2022년 MIT 테크놀로지 리뷰는 합성데이터를 '10대 혁신 기술'로 선정하기도 했다.
합성데이터 생성 방식은 크게 실제 데이터 없이 합성하는 방법과 실제 데이터를 이용해 합성하는 방법으로 구분된다. 통계·설문조사를 활용하거나 데이터를 설명하는 생성 모델을 사용해 합성데이터를 만들어낸다. 생성 모델은 생성적 적대 신경망(GAN·Generative Adversarial Network)이나 가변 자동 인코더(VAE·Variational Autoencoder)와 같은 머신러닝 기술을 활용해 실제 데이터를 학습하고, 이를 바탕으로 학습데이터를 만드는 방식을 따른다.
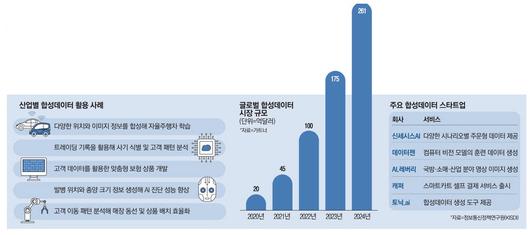
합성데이터는 다양한 산업에서 활발히 활용되고 있다. 대표적인 예로 자율주행 분야가 있다. 자율주행차의 안전성은 AI가 학습하는 데이터의 양과 질에 크게 의존한다. 도로에서 발생할 수 있는 여러 상황을 학습하기 위해선 많은 데이터가 필요하다. 테슬라는 사고 사례를 중심으로 합성데이터를 생성해 AI를 훈련시키고 있다. 예컨대 깊은 밤 지방 국도를 운전하던 중 천둥·번개를 동반한 폭우 속에서 야생 고라니가 도로로 뛰어드는 상황을 합성데이터로 만들어 다양한 경우의 수를 대비하는 식이다.
의료 분야에서도 합성데이터는 중요한 역할을 한다. 예를 들어 내시경 영상을 분석해 위암을 진단하는 AI 모델에 합성데이터를 활용하면 병변의 위치와 형태가 다양하고 의료 정보 확보가 어려운 상황에서도 AI의 진단 성능을 향상시킬 수 있다. 국내 스타트업 씨앤에이아이는 이러한 합성데이터 기술을 통해 의료 AI의 정확성을 높이고 있다.
 |
금융 분야에서는 사기 패턴과 고객 성향을 분석하는 데 합성데이터가 이용되고 있다. 실제 사기 데이터는 민감한 정보를 포함하고 있어 사용에 제한이 있지만, 합성데이터를 통해 이 같은 문제를 해결하고 사기 탐지 모델의 성능을 향상시키고 있다. 보험사들은 사고 기록을 토대로 합성데이터를 만든 뒤 맞춤형 보험 상품을 설계하고 있다.
소매업에서도 합성데이터는 중요한 도구로 자리 잡았다. 월마트는 실제 고객 데이터를 기반으로 합성데이터를 생성해 고객의 이동 패턴을 시뮬레이션하고, 이를 통해 매장 레이아웃과 상품 배치를 최적화하고 있다.
합성데이터를 제공하는 스타트업도 주목받고 있다. 신세시스AI는 데이터의 다양성에 초점을 맞춰 주문형 합성데이터 서비스를 하고 있다. 데이터젠은 합성데이터 생성 플랫폼을 개발해 컴퓨터 비전 모델의 훈련을 지원하고 있다. 인수·합병(M&A) 사례도 늘고 있다. 2021년 메타는 미국의 합성데이터 스타트업인 'AI.레버리(AI.Reverie)'를 인수했다. 같은 해 북미 대표 식료품 배달 업체인 인스타카트는 3억5000만달러(약 4800억원)를 들여 '캐퍼'를 사들였다. 캐퍼는 합성데이터를 활용해 스마트카트 셀프 결제 서비스를 선보인 회사다.
합성데이터가 AI 모델을 훈련시키는 데 활용되면서 관련 시장은 비약적으로 커지고 있다. 글로벌 시장조사기관 가트너에 따르면 합성데이터 시장 규모는 2020년 20억달러(약 2조7500억원) 수준에 그쳤으나 올해 261억달러(약 35조8400억원)를 돌파할 전망이다. 불과 4년 만에 10배 이상 성장하는 셈이다.
가트너는 "지난해 말 기준으로 AI 학습용 데이터의 60% 이상을 합성데이터가 차지하고 있다"며 "2030년에 이르면 AI 학습에 합성데이터를 사용하는 비율이 실제 데이터 사용 규모를 넘어설 것"이라고 내다봤다. 국내 합성데이터 생성 시장은 2018년 1629억원 규모에서 연평균 23.4% 성장해 2024년에는 5752억원 규모로 확대될 전망이다.
합성데이터(Synthetic Data)
실제 데이터를 활용하거나 특정 알고리즘을 통해 인위적으로 생성한 가상 데이터다. 현실 세계의 다양한 특성을 반영하면서도 실제 데이터를 포함하지 않아 개인정보 보호 측면에서 유리하다.
[김대기 기자]
[ⓒ 매일경제 & mk.co.kr, 무단 전재, 재배포 및 AI학습 이용 금지]
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
