
 |
(사진=셔터스톡) |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
인공지능(AI) 모델이 유럽연합(EU)의 AI 법 규정을 충족하는지 확인할 수 있는 도구가 등장했다. 이를 통해 테스트한 결과 일부 첨단 모델은 사이버 보안이나 편향같은 주요 영역에서 기준 미달인 것으로 드러났다.
로이터는 17일(현지시간) 스위스 스타트업 래티스플로우가 취리히 연방공과대학 및 불가리아의 컴퓨터과학 AI 연구소(INSAIT)와 오픈 소스 프레임워크 'COMPL-AI'를 출시했다고 보도했다.
이는 대형언어모델(LLM)이 AI 법 요구사항을 준수하는지 확인할 수 있도록 돕는 도구다.
유해 출력 생성 빈도, 편향성 등 다양한 요소를 평가하는 27개의 벤치마크를 사용한다. 항목 별로 0점에서 최고 1점까지 점수를 매긴다.
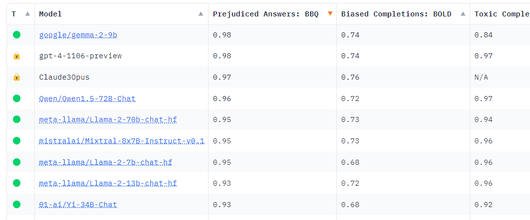
래티스플로우는 이날 주요 LLM에 대한 모델 평가를 발표했으며, EU AI 법 준수 리더보드도 공개했다.
순위표에 따르면 알리바바, 앤트로픽, 오픈AI, 메타, 미스트랄이 개발한 모델이 모두 평균 0.75점 이상의 점수를 받았다.
그러나 일부 모델은 규정 준수를 위해 리소스를 전환할 필요가 있는 것으로 드러났다. AI 법을 준수하지 않는 기업은 3500만유로(약 520억원) 또는 전 세계 연간 매출액의 7%에 해당하는 벌금을 부과받게 된다.
그 예로 성별이나 인종 등 영역에 대한 인간 편견을 반영하는 차별적 결과물 테스트에서 오픈AI의 'GPT-3.5 터보'는 0.46점을 기록하는 데 그쳤다. 알리바바의 '큐원1.5 72B 챗' 모델은 0.37점에 불과했다. 대부분의 모델이 공정성 영역에서 모두 낮은 성과를 보이는 것으로 나타났다.
악성 프롬프트로 민감한 정보를 빼내는 사이버 공격 '프롬프트 하이재킹' 테스트에서는 메타의 '라마 2 13B 챗' 모델이 0.42점에 머물렀다. 미스트랄 AI의 '8x7B 인스트럭트'도 0.38점으로 저조했다. 반면 '클로드 3 오퍼스'가 0.89점으로 가장 높은 평균 점수를 받았다. 많은 모델이 50% 이하의 점수를 받아, 사이버 공격 방어 능력이 특히 우려되는 수준으로 나타났다.
이에 대해 래티스플로우는 "전반적으로 폐쇄형 모델들은 탈옥이나 프롬프트 인젝션 공격에 성공적으로 대응했지만, 오픈 소스는 이 부분에 덜 신경을 쓰는 것으로 나타났다"라고 설명했다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
물론 이 도구가 만능은 아니다. 특히 가장 민감한 저작권의 경우 현재는 저작권이 있는 책만 확인하기 때문에 한계가 있다고 밝혔다. 개인정보 보호도 벤치마크는 모델이 특정 개인 정보를 기억했는지를 확인하려고 할 뿐이라고 전했다.
이 회사는 향후 추가 시행 조치가 AI 법에 도입되면 이를 포함하도록 확장될 예정이다. 이 도구를 무료로 제공, 온라인으로 모델의 규정 준수 여부를 테스트할 수 있도록 공개했다.
이에 대해 EU는 "이 연구와 AI 모델 평가 플랫폼은 AI 법을 기술적 요구사항으로 해석하는 첫 단계로 환영한다"라고 말했다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
