
AI 음성 스타트업 일레븐랩스가 이미지, 영상, 음성, 음악, 효과음 생성 모델을 하나의 파이프라인으로 통합해 콘텐츠 기획부터 제작까지 한곳에서 설계하고 실행할 수 있는 제작 플랫폼을 출시했다.
일레븐랩스는 14일(현지시간) 제작 플랫폼 일레븐크리에이티브(ElevenCreative)에 새로운 기능 '플로우(Flows)'를 도입하며 AI 기반 콘텐츠 제작 방식을 크게 확장했다.
플로우는 이미지, 영상, 음성, 음악, 효과음 등 다양한 생성 AI 모델을 하나의 파이프라인으로 연결해 제작할 수 있다.
노드 기반(visual node-based) 워크플로우 구조로 작동한다. 사용자는 캔버스 위에서 여러 AI 모델을 연결해 이미지 생성, 영상 생성, 텍스트 기반 음성 생성(Text-to-Speech), 립싱크 적용, 효과음(SFX) 추가, 음악 삽입 등 다양한 제작 과정을 하나의 흐름으로 구성할 수 있다.
예를 들어, '소라'나 '비오' 등 타사의 모델로 영상 생성 이후 음성 생성, 립싱크 적용, 배경 음악 추가까지의 과정을 하나의 흐름으로 연결하면 전체 콘텐츠 제작 파이프라인이 자동으로 실행된다. 또 특정 단계만 수정할 수 있어 전체 파이프라인을 처음부터 다시 만들지 않고도 결과물을 반복적으로 개선할 수 있다.
이처럼 핵심 특징은 재사용 가능한 구조다. 하나의 플로우를 한번 설계해 두면, 아바타만 변경하거나 제품 이미지나 스크립트를 바꾸고 다른 음성을 적용하는 방식으로 동일한 제작 구조를 반복 실행할 수 있다.
이를 통해 기업은 여러 버전의 광고 콘텐츠를 빠르게 테스트할 수 있으며, 다양한 스타일의 영상과 음성 조합을 자동으로 생성할 수 있다.
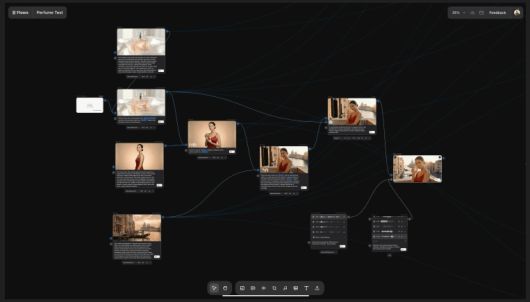 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
지금까지 AI 콘텐츠 제작 과정에서는 여러 가지 불편함이 따랐다. 이미지, 영상, 음성 등 작업마다 서로 다른 AI 도구를 따로 사용해야 했고, 작업 결과물을 계속 내보내고 다시 업로드하는 과정을 반복해야 했다. 여러 버전을 관리하는 것도 복잡해지는 문제가 있었다. 이러한 이유로 후반 제작(post-production) 단계에서 많은 수작업이 발생하는 경우가 많았다.
플로우는 이러한 문제를 해결하기 위해 멀티모달 AI 모델을 자동으로 연결하는 파이프라인을 제공한다. 먼저 통합 자산 관리 기능을 통해 음성 클론, 음악, 효과음 등 다양한 미디어 자산을 하나의 프로젝트 안에서 관리할 수 있다. 또 조건 기반 로직을 지원해 스크립트의 상황이나 조건에 따라 서로 다른 음성 스타일을 적용할 수 있다.
이와 함께 API 기반 확장성을 제공해 개발자가 자동화된 콘텐츠 생성 시스템을 구축할 수 있도록 했으며, 멀티모달 통합 구조를 통해 텍스트·음성·영상 생성 모델을 하나의 워크플로우로 연결해 사용할 수 있다.
업계에서는 이번 기능이 AI 콘텐츠 제작이 단일 도구 중심에서 '에이전트형 제작 시스템(agentic system)'으로 이동하는 흐름을 보여준다고 평했다. 플로우처럼 여러 AI 모델을 하나의 파이프라인으로 연결해 자동 실행하는 방식이 보편화하면, 콘텐츠 제작은 AI가 단계별로 협업하는 자동화 시스템으로 바뀔 가능성이 크다는 것이다.
한편, 일레븐랩스는 앞으로 2~3년 내 기업공개(IPO)를 준비하고 있는 것으로 알려졌다.
박찬 기자 cpark@aitimes.com
<저작권자 Copyright ⓒ AI타임스 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
