
네이버 PC·모바일 검색 내 새로운 ‘스마트블록’ 개발자 3인 인터뷰
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
국내 최대 포털 네이버가 검색 전반에 생성형 AI 기술을 속속 심고 있다. 생성형 AI시대의 신호탄을 쏜 대화형 인공지능(AI) 챗봇 ‘챗GPT’로 검색엔진 종말론이 급부상한 상황에서 오히려 생성형 AI 모델을 검색 본연의 기능을 강화할 도구 중 하나로 삼겠다는 전략이다.
앞서 네이버는 지난해 9월 생성형 AI 검색 서비스인 Cue: 베타 서비스를 출시해 대화형 검색으로 정보 탐색 방식을 확대했다. 이달부터는 PC·모바일 검색 서비스에 생성형 AI 기술을 접목한 ‘스마트블록’ 베타 서비스를 시작했다.
지난 22일 <디지털데일리>는 경기 성남시 분당구 네이버 1784에서 스마트블록 모델링 담당 개발자인 김세훈, 이영준, 최나영 네이버 발견/탐색 프로덕트 에어서치 하이퍼 퍼스널라이즈드 서치(AiRSearch Hyper-personalized search) 연구원들을 만나 스마트블록 서비스 개발 배경을 들었다.
스마트블록은 자체 AI 기반 검색 기술인 ‘에어서치(AiRSearch)’를 통해 선별된 개인 맞춤형 검색 결과 피드다. 블로그, 카페, 동영상 등 네이버 검색 결과 페이지 내에 흩어져 있던 문서들을 높은 적합도 순서로 최상단부터 노출하는 방식을 택한다.
기존 네이버 검색은 일부 길고 복잡한 검색어에 대해 단어 간 관계를 파악하기 어려워 사용자가 원하는 문서를 정확하게 주지 못했다. 하지만 생성형 AI를 활용해 단어 간 맥락을 정확하게 파악하고 더 개선된 검색 랭킹 결과를 제공할 수 있게 됐다.
‘서울 쪽 아기랑 가기 좋은 무료입장 가능한 곳’이라는 검색어에서 ‘서울 쪽’, ‘아기랑’, ‘무료입장’ 사이의 ‘가기 좋은’이라는 표현에 대해 ‘갈만한 곳’으로 맥락을 확장해 해석하는 식이다. 어떻게 이것이 가능할까.
네이버는 그간 축적된 거대한 사용자 경험 데이터 통계 기반의 검색 방법론들과 딥러닝 모델들을 사용해 사용자 검색 니즈에 맞는 문서 랭킹 결과를 제공해 왔다. 다만, 일부 길고 복잡한 검색어(롱테일 질의)는 검색되는 횟수가 매우 적어 축적된 사용자 피드백이 상대적으로 부족했다.
최나영 연구원은 “통계 기반의 검색 방법론들은 각 단어를 독립적으로 보기에 길고 복잡한 내용의 검색어 맥락을 파악하는 데 어려움이 있다”며 “딥러닝 모델의 경우 이러한 문제를 풀기 위한 학습 데이터가 필요한데, 보통 단어 중심의 검색 방식을 쓰다 보니 (롱테일 질의에 대해) 정확한 학습 데이터를 만들기가 쉽지 않았다”라고 말했다.
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
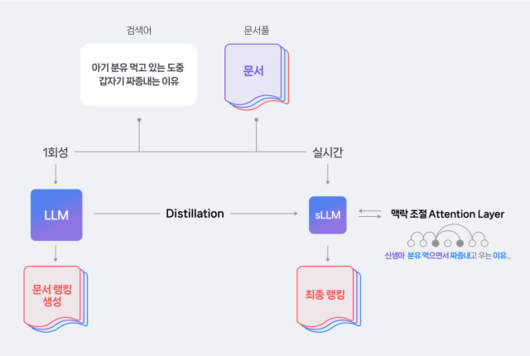
문제는 이런 LLM이 문서를 랭킹하는 데 너무 오랜 시간이 걸린다는 점이었다. LLM은 이름처럼 거대한 크기와 느린 속도 때문에 기존 검색 형태에 그대로 적용하기가 어렵다. 원하는 성능은 유지하면서도 서비스에 적용 가능한 수준으로, 작고 속도가 빠른 AI 모델(sLLM)을 만드는 ‘경량화’ 기술이 필요한 이유다.
이영준 연구원은 “사용자가 네이버에서 검색하면 그 결과를 실시간으로 보여줘야 하므로 무거운 LLM을 그대로 사용할 수 없었다”며 “생성형 AI의 언어 이해 능력을 검색에서도 사용할 수 있도록 LLM 언어 이해 능력을 sLLM에 옮기는 연구를 진행했다”라고 덧붙였다.
모델의 크기 차이 탓에 LLM의 모든 능력을 sLLM에 옮기는 것은 불가능하다. 스마트블록 모델링 담당 개발진은 ‘문서 랭킹에만 꼭 필요한 언어 이해 능력’만을 옮기는 것에 집중했고, 그 핵심에 sLLM이 맥락을 스스로 조절할 수 있어야 한다는 점을 파악했다.
가령 검색어 ‘아기가 분유 먹고 있는 도중 짜증내는 이유’와 문서 ‘신생아가 분유 먹으면서 짜증내고 우는 이유’를 보면, sLLM은 ‘아기’와 ‘신생아’, ‘먹고 있는 도중’과 ‘먹으면서’가 단어는 다르나 맥락이 유사하다는 것을 알아야 한다. ‘분유’와 ‘이유’ 같이 서로 일치하는 단어의 중요성 또한 잊지 말아야 한다.
경량화는 LLM에 문서들을 리랭킹하도록 해 도출된 결과 데이터를 가지고 sLLM에 이 결과 데이터를 따라 하도록 학습시키는 원리다. sLLM은 크기를 줄인 만큼 언어 이해 능력이 LLM 보다 부족할 수 있다. 이에 개발진은 sLLM이 상황에 따라 단어의 유사도를 고려하는 것을 스스로 조절할 수 있도록 ‘맥락 조절 어텐션 레이어(Attention Layer)’를 추가한 독자적인 구조를 설계했다. 문서 리랭킹 테스크에서 LLM 만큼 성능을 내는 데 성공한 셈이다.
네이버는 생성형 AI 기술을 검색 품질을 높이는 데 지속 활용함으로써 기존 검색 생태계 기능들의 상호보완성을 극대화한다는 목표다. Cue:는 여러 건의 적합 문서로부터 요약·정리된 답변을 생성하고 대화형으로 질문을 이어갈 수 있다는 장점이 있다. 신규 스마트블록은 향후 Cue: 답변이 검색 결과로 노출돼 요약·정리된 답변을 확인한 뒤에도 하단에서 추가적인 정보를 찾거나 새로운 정보를 발견하고 탐색할 수 있다.
김세훈 연구원은 “Cue:는 할루시네이션을 최소화하기 위해 검색 결과를 활용해 답변을 생성하므로 문서 랭킹 품질이 높아지면 Cue: 답변 품질도 올라가는 시너지가 있다”며 “신규 스마트블록이 통합검색에 적용됨으로써 Cue: 답변 품질도 높아지고, 향후 통합검색에 Cue: 답변 결과 노출을 점차 늘리며 통합검색 품질도 좋아진다고 볼 수 있다”라고 강조했다.
통합검색에 적용된 신규 스마트블록은 최근 시작한 베타 서비스를 거쳐 오는 5월 말 전면 출시된다. 네이버는 앞으로 새롭게 등장할 여러 가지 기술을 시의적절하게 접목해 검색 서비스를 한층 개선하고, 쇼핑·페이·로컬·광고 등 여러 서비스와도 유기적인 연계를 강화할 예정이다.
- Copyright ⓒ 디지털데일리. 무단전재 및 재배포 금지 -
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
