
 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
대규모 언어모델 기반 AI 서비스의 비용 구조에 균열이 생겼다. 데이터센터에 집중돼 있던 연산 방식을 벗어나, 주변에 이미 깔려 있는 자원을 활용하는 새로운 선택지가 제시됐다.
KAIST는 전기및전자공학부 한동수 교수 연구팀이 소비자급 GPU를 활용해 거대언어모델 인프라 비용을 크게 낮출 수 있는 기술 'SpecEdge'를 개발했다고 밝혔다. 고가의 데이터센터 GPU 사용을 줄이고, 개인 PC나 소형 서버에 탑재된 저렴한 GPU를 함께 활용하는 방식이다.
 |
왼쪽부터 KAIST 전기및전자공학부 박진우 박사, 조승근 석사과정, 한동수 교수 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
SpecEdge는 데이터센터 GPU와 엣지 GPU가 역할을 나눠 추론을 수행한다. 엣지 GPU에 배치된 소형 언어모델이 먼저 확률이 높은 토큰 시퀀스를 빠르게 생성하고, 데이터센터의 대규모 모델이 이를 검증하는 구조다. 이 과정에서 엣지 GPU는 서버 응답을 기다리지 않고 연속적으로 토큰을 생성해 전체 처리 효율을 끌어올린다.
실험 결과는 분명했다. 기존처럼 데이터센터 GPU만 사용하는 방식과 비교해 토큰당 비용은 약 67.6% 낮아졌다. 비용 효율성은 1.91배, 서버 처리량은 2.22배 향상됐다. 일반적인 인터넷 환경에서도 안정적으로 작동해, 별도의 고가 네트워크 없이 실제 서비스 적용이 가능하다는 점도 확인됐다.
서버 구조 역시 엣지 GPU 다수를 동시에 감당하도록 설계됐다. 여러 엣지에서 올라오는 검증 요청을 효율적으로 처리해 GPU 유휴 시간을 줄였고, 같은 자원으로 더 많은 요청을 소화할 수 있는 서빙 환경을 구현했다. 데이터센터 자원의 활용 밀도를 높이는 방향이다.
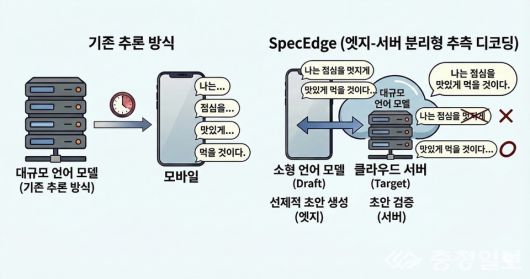 |
연구팀이 개발한 SpecEdge의 기존과 비교 개념도 |
<이미지를 클릭하시면 크게 보실 수 있습니다> |
이번 연구는 거대언어모델 연산을 데이터센터에만 묶어두던 기존 관행에서 벗어나, 연산을 공간적으로 분산시키는 가능성을 제시했다. 향후 스마트폰, 개인용 컴퓨터, 신경망 처리장치 등으로 확장될 경우 고품질 AI 서비스의 이용 문턱이 크게 낮아질 수 있다는 평가다.
한동수 교수는 "사용자 주변에 이미 존재하는 엣지 자원까지 LLM 인프라로 활용하는 것이 목표"라며 "AI 서비스 제공 비용을 낮춰 더 많은 이들이 고급 AI를 활용할 수 있는 환경을 만들고자 했다"고 설명했다.
이번 연구에는 박진우 박사와 조승근 석사과정이 참여했다. 연구 성과는 12월 미국 샌디에이고에서 열린 인공지능 분야 최고 권위 국제 학회 NeurIPS에서 스포트라이트 논문으로 발표됐다. 해당 논문은 상위 3.2%에 해당하는 성과로 평가받았다. /대전=이한영기자
<저작권자 Copyright ⓒ 충청일보 무단전재 및 재배포 금지>
이 기사의 카테고리는 언론사의 분류를 따릅니다.
기사가 속한 카테고리는 언론사가 분류합니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
언론사는 한 기사를 두 개 이상의 카테고리로 분류할 수 있습니다.
